- Authors
- Name
- はじめに
- キャッシュ戦略の概要
- 1. Cache-Aside(Lazy Loading)
- 2. Read-Through
- 3. Write-Through
- 4. Write-Behind(Write-Back)
- 5. Refresh-Ahead
- 6. Cache Stampede の防止
- TTL 戦略
- Redis データ構造の活用
- キャッシュモニタリング
- 戦略選択ガイド
- クイズ
- まとめ
- 参考資料
はじめに
キャッシュはアプリケーションパフォーマンス最適化の中核戦略です。しかし「キャッシュを使えば速くなる」程度の理解だけでは、本番環境でさまざまな問題に直面します。キャッシュの整合性、キャッシュスタンピード、メモリ管理など実務で遭遇する課題を解決するには、正しいキャッシュ戦略の選択が不可欠です。
キャッシュ戦略の概要
┌─────────────────────────────────────────────────────┐
│ キャッシュ戦略の分類 │
├──────────────────┬──────────────────────────────────┤
│ 読み取り戦略 │ 書き込み戦略 │
├──────────────────┼──────────────────────────────────┤
│ Cache-Aside │ Write-Through │
│ Read-Through │ Write-Behind (Write-Back) │
│ Refresh-Ahead │ Write-Around │
└──────────────────┴──────────────────────────────────┘
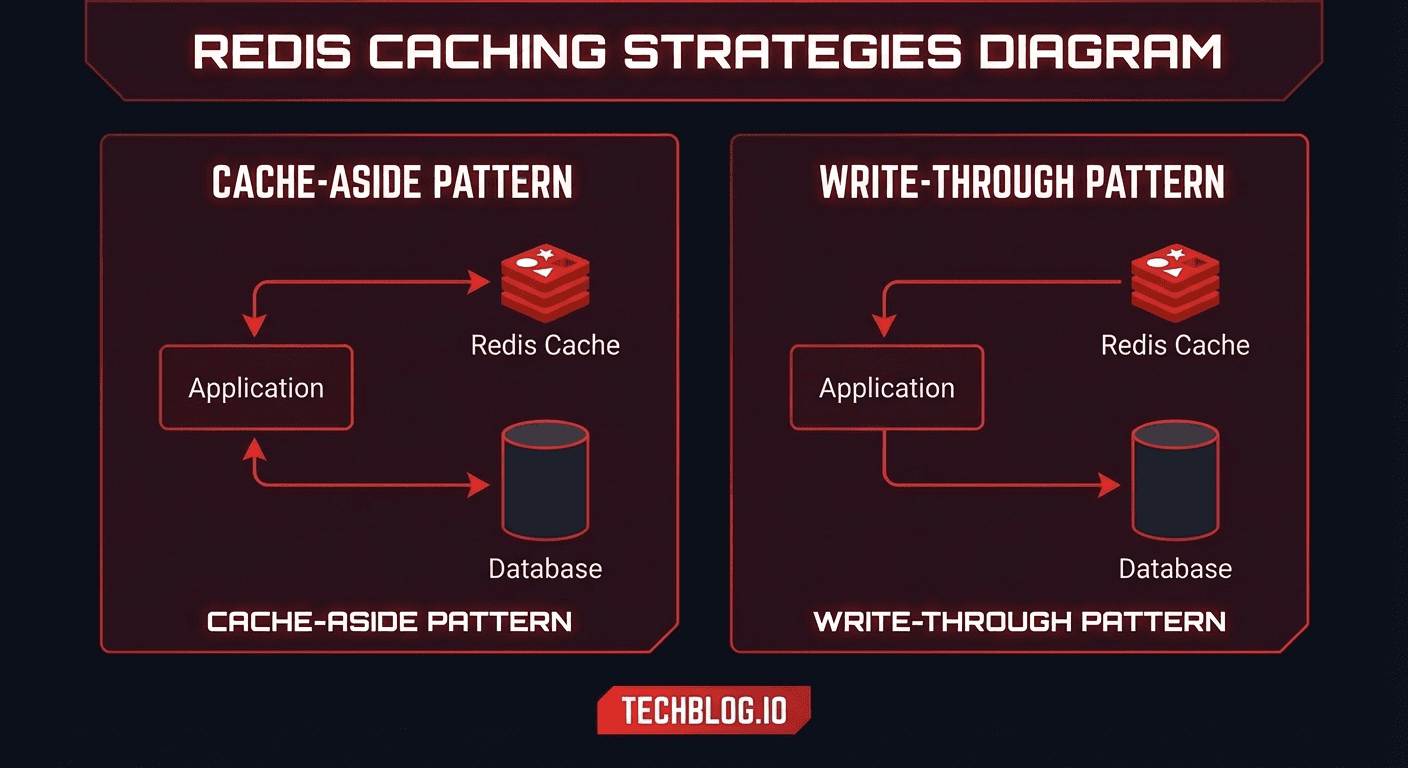
1. Cache-Aside(Lazy Loading)
最も広く使われるパターンで、アプリケーションがキャッシュを直接管理します。
読み取りフロー:
[App] → Cache hit? → [Redis] → データ返却
↓ miss
[App] → [Database] → データ返却
↓
[App] → [Redis] キャッシュ保存
import redis
import json
from typing import Optional
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
class UserService:
def get_user(self, user_id: int) -> Optional[dict]:
cache_key = f"user:{user_id}"
# 1. キャッシュ確認
cached = r.get(cache_key)
if cached:
return json.loads(cached)
# 2. Cache Miss → DB 問い合わせ
user = self.db.query("SELECT * FROM users WHERE id = %s", user_id)
if not user:
# Negative caching: 存在しないデータもキャッシュ(短い TTL)
r.setex(cache_key, 60, json.dumps(None))
return None
# 3. キャッシュ保存
r.setex(cache_key, 3600, json.dumps(user))
return user
def update_user(self, user_id: int, data: dict):
# DB 更新
self.db.execute("UPDATE users SET ... WHERE id = %s", user_id)
# キャッシュ無効化(削除)
cache_key = f"user:{user_id}"
r.delete(cache_key)
# 注意: キャッシュの更新ではなく削除!
# 次の読み取り時に最新データで再キャッシュ
メリット: 実装がシンプル、必要なデータのみキャッシュ、キャッシュ障害時はDBにフォールバック デメリット: 初回リクエストは常に遅い(Cold Start)、データ不整合の可能性
2. Read-Through
キャッシュがデータロードを担当します。アプリケーションは常にキャッシュだけを参照します。
class ReadThroughCache:
"""
キャッシュがDBクエリを代行
アプリケーションはキャッシュのみを呼び出す
"""
def __init__(self, redis_client, db, default_ttl=3600):
self.redis = redis_client
self.db = db
self.ttl = default_ttl
def get(self, key: str, loader_fn=None) -> Optional[dict]:
# キャッシュ確認
cached = self.redis.get(key)
if cached:
return json.loads(cached)
# Cache Miss → loader 関数でデータをロード
if loader_fn:
data = loader_fn()
if data is not None:
self.redis.setex(key, self.ttl, json.dumps(data))
return data
return None
# 使用例
cache = ReadThroughCache(r, db)
def get_product(product_id: int):
return cache.get(
f"product:{product_id}",
loader_fn=lambda: db.query(
"SELECT * FROM products WHERE id = %s", product_id
)
)
3. Write-Through
書き込みがキャッシュを経由してDBに同期的に伝播します。
class WriteThroughCache:
"""
書き込み: App → Cache → DB(同期)
読み取り: App → Cache(常に最新)
"""
def write(self, key: str, data: dict, db_writer_fn=None):
# 1. まずキャッシュに書き込み
self.redis.setex(key, self.ttl, json.dumps(data))
# 2. DBに同期的に書き込み
if db_writer_fn:
db_writer_fn(data)
return data
def get(self, key: str) -> Optional[dict]:
# キャッシュは常に最新なのでキャッシュからのみ読み取り
cached = self.redis.get(key)
if cached:
return json.loads(cached)
return None
# 使用例
cache = WriteThroughCache(r, db)
def update_inventory(product_id: int, quantity: int):
data = {"product_id": product_id, "quantity": quantity}
cache.write(
f"inventory:{product_id}",
data,
db_writer_fn=lambda d: db.execute(
"UPDATE inventory SET quantity = %s WHERE product_id = %s",
d["quantity"], d["product_id"]
)
)
メリット: キャッシュとDBの整合性を保証 デメリット: 書き込みレイテンシ増加(キャッシュ + DB の2回)、使わないデータもキャッシュ
4. Write-Behind(Write-Back)
書き込みをキャッシュにのみ行い、DB反映は非同期で遅延させます。
import threading
from collections import defaultdict
class WriteBehindCache:
"""
書き込み: App → Cache(即時) → DB(非同期、バッチ)
高い書き込みスループットが必要な場合
"""
def __init__(self, redis_client, db, flush_interval=5):
self.redis = redis_client
self.db = db
self.dirty_keys = set()
self.flush_interval = flush_interval
self._start_flusher()
def write(self, key: str, data: dict):
# キャッシュにのみ即時書き込み
self.redis.setex(key, 7200, json.dumps(data))
# Dirty マーク(DB反映が必要)
self.redis.sadd("dirty_keys", key)
def _start_flusher(self):
"""定期的に Dirty データをDBにバッチ反映"""
def flush():
while True:
try:
# Dirty キーを取得
dirty_keys = self.redis.smembers("dirty_keys")
if dirty_keys:
pipe = self.db.pipeline()
for key in dirty_keys:
data = self.redis.get(key)
if data:
pipe.add_to_batch(key, json.loads(data))
pipe.execute() # バッチ DB 書き込み
# Dirty マークを削除
self.redis.srem("dirty_keys", *dirty_keys)
except Exception as e:
print(f"Flush error: {e}")
threading.Event().wait(self.flush_interval)
thread = threading.Thread(target=flush, daemon=True)
thread.start()
メリット: 非常に高速な書き込みパフォーマンス、DB負荷の軽減 デメリット: データ損失のリスク(キャッシュ障害時)、実装が複雑
5. Refresh-Ahead
TTL 期限切れの前にキャッシュを事前に更新します。
import time
class RefreshAheadCache:
"""
TTL の一定割合の時点でバックグラウンドでキャッシュを更新
例: TTL 3600秒、factor 0.8 → 2880秒(80%)の時点で更新開始
"""
def __init__(self, redis_client, refresh_factor=0.8):
self.redis = redis_client
self.refresh_factor = refresh_factor
def get(self, key: str, ttl: int, loader_fn=None):
cached = self.redis.get(key)
if cached:
# 残り TTL を確認
remaining_ttl = self.redis.ttl(key)
threshold = ttl * (1 - self.refresh_factor)
if remaining_ttl < threshold:
# バックグラウンドで事前に更新
self._async_refresh(key, ttl, loader_fn)
return json.loads(cached)
# Cache Miss
if loader_fn:
data = loader_fn()
self.redis.setex(key, ttl, json.dumps(data))
return data
return None
def _async_refresh(self, key, ttl, loader_fn):
"""非同期でキャッシュを更新(ロックで重複防止)"""
lock_key = f"refresh_lock:{key}"
if self.redis.set(lock_key, "1", nx=True, ex=30):
# ロック取得成功 → 更新
threading.Thread(
target=self._refresh,
args=(key, ttl, loader_fn, lock_key),
daemon=True
).start()
def _refresh(self, key, ttl, loader_fn, lock_key):
try:
data = loader_fn()
self.redis.setex(key, ttl, json.dumps(data))
finally:
self.redis.delete(lock_key)
6. Cache Stampede の防止
TTL 期限切れ時に大量のリクエストが同時にDBを叩く Cache Stampede 問題の解決:
class StampedeProtectedCache:
def get_with_lock(self, key: str, ttl: int, loader_fn):
"""分散ロックで1つのリクエストのみDBに問い合わせ"""
cached = self.redis.get(key)
if cached:
return json.loads(cached)
lock_key = f"lock:{key}"
# 分散ロックを試行
if self.redis.set(lock_key, "1", nx=True, ex=10):
try:
# ロック取得 → DB問い合わせ & キャッシュ更新
data = loader_fn()
self.redis.setex(key, ttl, json.dumps(data))
return data
finally:
self.redis.delete(lock_key)
else:
# ロック失敗 → 少し待ってからキャッシュを再確認
time.sleep(0.1)
cached = self.redis.get(key)
if cached:
return json.loads(cached)
# まだなければ直接DB問い合わせ
return loader_fn()
def get_with_probabilistic_refresh(self, key: str, ttl: int, loader_fn, beta=1.0):
"""確率的早期更新(XFetch アルゴリズム)"""
cached = self.redis.get(key)
if cached:
data = json.loads(cached)
remaining_ttl = self.redis.ttl(key)
delta = ttl - remaining_ttl # 経過時間
# 確率的に早期更新をトリガー
# TTL 期限切れが近いほど更新確率が上昇
import random, math
if delta > 0:
prob = math.exp(-remaining_ttl / (beta * delta))
if random.random() < prob:
# 早期更新
new_data = loader_fn()
self.redis.setex(key, ttl, json.dumps(new_data))
return new_data
return data
# Cache Miss
data = loader_fn()
self.redis.setex(key, ttl, json.dumps(data))
return data
TTL 戦略
# データ種別ごとの TTL ガイド
TTL_STRATEGIES = {
# 頻繁に変更されるデータ
"session": 1800, # 30分
"rate_limit": 60, # 1分
"realtime_stats": 10, # 10秒
# たまに変更されるデータ
"user_profile": 3600, # 1時間
"product_detail": 1800, # 30分
"api_response": 300, # 5分
# ほとんど変更されないデータ
"config": 86400, # 24時間
"country_list": 604800, # 7日
"static_content": 2592000, # 30日
# Negative cache(存在しないデータ)
"not_found": 60, # 1分(短く!)
}
# TTL に若干のランダム性を追加(Stampede 防止)
import random
def ttl_with_jitter(base_ttl: int, jitter_pct: float = 0.1) -> int:
"""TTL に ±10% のランダム偏差を追加"""
jitter = int(base_ttl * jitter_pct)
return base_ttl + random.randint(-jitter, jitter)
# 使用: r.setex(key, ttl_with_jitter(3600), value)
Redis データ構造の活用
# 1. String — シンプルなキャッシュ
r.setex("user:123", 3600, json.dumps(user_data))
# 2. Hash — 部分更新が必要な場合
r.hset("user:123", mapping={
"name": "Youngju",
"email": "yj@example.com",
"login_count": 42
})
r.hincrby("user:123", "login_count", 1) # 部分更新
# 3. Sorted Set — ランキング/リーダーボード
r.zadd("leaderboard", {"player1": 100, "player2": 85, "player3": 92})
top_3 = r.zrevrange("leaderboard", 0, 2, withscores=True)
# 4. List — 最近のアクティビティフィード
r.lpush("feed:user:123", json.dumps(activity))
r.ltrim("feed:user:123", 0, 99) # 最新100件のみ保持
# 5. Set — 重複排除
r.sadd("online_users", "user:123", "user:456")
online_count = r.scard("online_users")
# 6. Stream — イベントログ
r.xadd("events:orders", {"action": "created", "order_id": "ORD-123"})
キャッシュモニタリング
# Redis INFO コマンドでキャッシュ効率を確認
info = r.info("stats")
hits = info["keyspace_hits"]
misses = info["keyspace_misses"]
hit_rate = hits / (hits + misses) * 100
print(f"Cache Hit Rate: {hit_rate:.1f}%")
# 目標: 95% 以上
# メモリ使用量の確認
memory_info = r.info("memory")
print(f"Used Memory: {memory_info['used_memory_human']}")
print(f"Peak Memory: {memory_info['used_memory_peak_human']}")
print(f"Fragmentation Ratio: {memory_info['mem_fragmentation_ratio']}")
# Redis CLI でモニタリング
redis-cli info stats | grep -E "keyspace_hits|keyspace_misses"
redis-cli info memory | grep "used_memory_human"
# スロークエリの確認
redis-cli slowlog get 10
# リアルタイムコマンドモニタリング
redis-cli monitor
戦略選択ガイド
┌─────────────────────────────────────────────────┐
│ どのキャッシュ戦略を使うべきか? │
├─────────────────────────────────────────────────┤
│ │
│ 読み取り中心? ──YES──> Cache-Aside │
│ │ (最も汎用的) │
│ NO │
│ │ │
│ 書き込み中心? ──YES──> Write-Behind │
│ │ (高い書き込みスループット)│
│ NO │
│ │ │
│ 整合性重要? ──YES──> Write-Through │
│ │ (キャッシュ-DB常時同期) │
│ NO │
│ │ │
│ レイテンシ敏感?──YES──> Refresh-Ahead │
│ (Cache Miss 最小化) │
└─────────────────────────────────────────────────┘
クイズ
Q1. Cache-Aside パターンでデータ更新時にキャッシュを「更新」せずに「削除」する理由は?
Race Condition の防止のためです。2つのリクエストが同時に更新すると、古いデータがキャッシュに残る可能性があります。削除すれば、次の読み取り時に最新データをDBから取得して再キャッシュします。
Q2. Cache Stampede とは何か、どう防ぐか?
人気のあるキャッシュキーの TTL が期限切れになった際に、大量のリクエストが同時にDBに問い合わせる現象です。分散ロック、確率的早期更新(XFetch)、Refresh-Ahead パターンで防止します。
Q3. Write-Behind パターンの最大のリスクは?
キャッシュ(Redis)障害時に、まだDBに反映されていないデータが失われる可能性があります。AOF/RDB 永続化設定と Write-Ahead Log でリスクを軽減できます。
Q4. Negative Caching とは?
DBに存在しないデータもキャッシュすることです。同じ存在しないキーへの繰り返しクエリがDBを叩くのを防ぎます。短い TTL(例: 60秒)を使用します。
Q5. TTL に Jitter を追加する理由は?
同時に作成されたキャッシュが一斉に期限切れとなり Cache Stampede が発生するのを防ぐためです。TTL に ±10% のランダム偏差を追加します。
Q6. Cache Hit Rate の推奨目標値は?
一般的に 95% 以上 を目標とします。80% 未満であればキャッシュ戦略を見直す必要があります。
Q7. Redis Hash が String より有利な状況は?
オブジェクトの一部のフィールドのみ更新する場合です。String はデータ全体をシリアライズ/デシリアライズする必要がありますが、Hash は個別フィールドを独立して読み書きできます。
まとめ
キャッシュ戦略は「Redis に入れれば終わり」ではありません。データの特性(読み取り/書き込み比率、整合性要件、更新頻度)に応じた適切な戦略を選択し、TTL 管理、Stampede 防止、モニタリングまで考慮してこそ、本番環境で安定的に運用できます。