- Authors
- Name
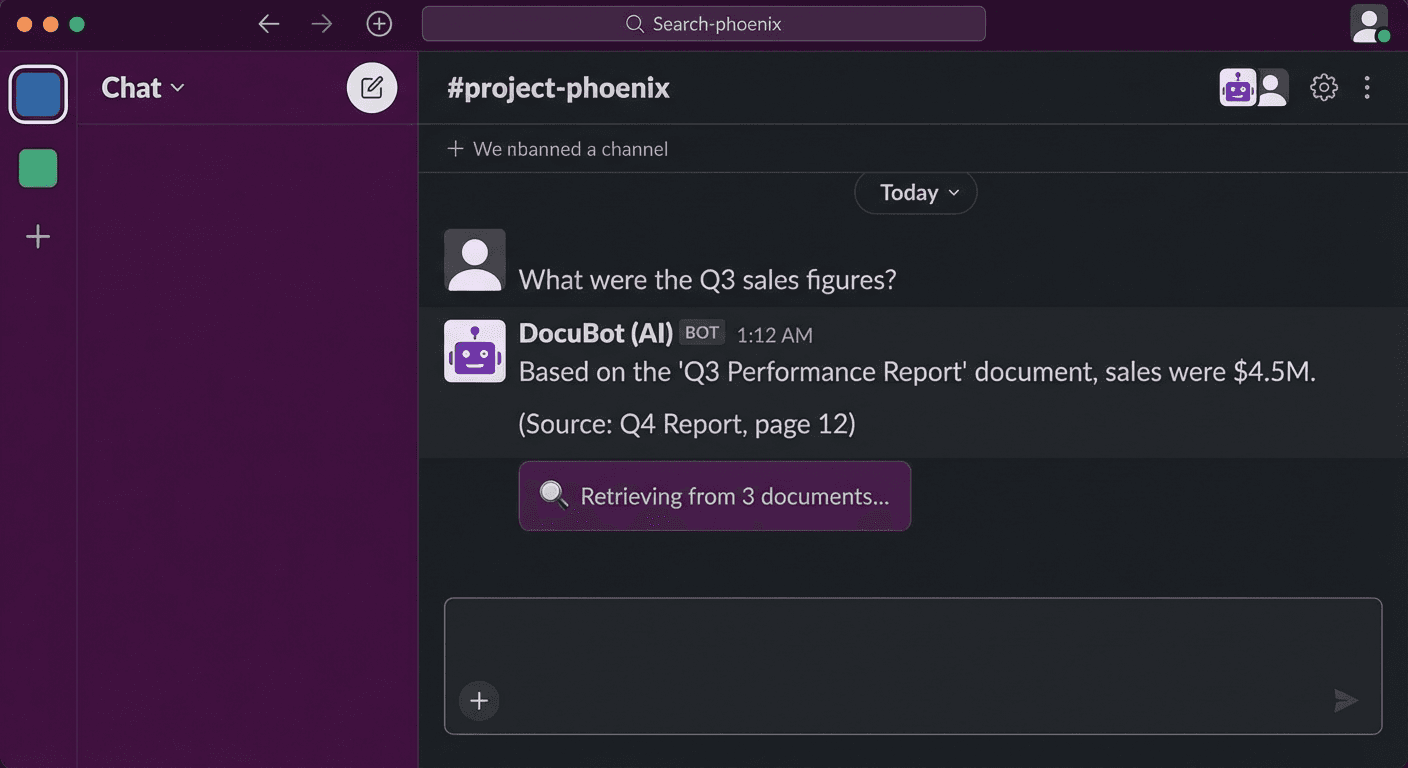
はじめに
「Confluenceのデプロイ手順ドキュメントはどこだっけ?」 「Kubernetesクラスターへのアクセス方法はどうだっけ?」
こういった質問に毎回人が答える代わりに、社内ドキュメントを検索するAIチャットボットを作りましょう。LangChain + RAG(Retrieval-Augmented Generation)+ Slack Botの組み合わせで、実践的なプロダクションレベルのチャットボットを構築します。
アーキテクチャ概要
# インデキシングパイプライン(オフライン)
# ドキュメント → チャンキング → エンベディング → ベクトルDB(ChromaDB)
# クエリパイプライン(オンライン)
# Slackメッセージ → エンベディング → ベクトル検索 → LLM生成 → Slack応答
プロジェクト設定
依存関係のインストール
mkdir slack-rag-bot && cd slack-rag-bot
# 仮想環境
python -m venv .venv
source .venv/bin/activate
# 依存関係
pip install \
langchain==0.2.16 \
langchain-openai==0.1.25 \
langchain-community==0.2.16 \
chromadb==0.5.3 \
slack-bolt==1.20.0 \
python-dotenv==1.0.1 \
unstructured==0.15.0 \
tiktoken==0.7.0
環境変数
# .env
OPENAI_API_KEY=sk-xxx
SLACK_BOT_TOKEN=xoxb-xxx
SLACK_APP_TOKEN=xapp-xxx
SLACK_SIGNING_SECRET=xxx
CHROMA_PERSIST_DIR=./chroma_db
DOCS_DIR=./documents
プロジェクト構造
slack-rag-bot/
├── .env
├── main.py # Slack Botエントリーポイント
├── indexer.py # ドキュメントインデキシング
├── rag_chain.py # RAGチェーン
├── config.py # 設定
├── documents/ # 社内ドキュメント(Markdown、PDFなど)
│ ├── deployment-guide.md
│ ├── k8s-access.md
│ └── onboarding.pdf
└── chroma_db/ # ベクトルDBストレージ
ドキュメントのインデキシング
ドキュメントの読み込みとチャンキング
# indexer.py
import os
from pathlib import Path
from langchain_community.document_loaders import (
DirectoryLoader,
UnstructuredMarkdownLoader,
PyPDFLoader,
TextLoader
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from dotenv import load_dotenv
load_dotenv()
def load_documents(docs_dir: str):
"""さまざまな形式のドキュメントを読み込む"""
documents = []
# Markdownファイル
md_loader = DirectoryLoader(
docs_dir,
glob="**/*.md",
loader_cls=UnstructuredMarkdownLoader,
show_progress=True
)
documents.extend(md_loader.load())
# PDFファイル
pdf_loader = DirectoryLoader(
docs_dir,
glob="**/*.pdf",
loader_cls=PyPDFLoader,
show_progress=True
)
documents.extend(pdf_loader.load())
# テキストファイル
txt_loader = DirectoryLoader(
docs_dir,
glob="**/*.txt",
loader_cls=TextLoader,
show_progress=True
)
documents.extend(txt_loader.load())
print(f"合計{len(documents)}件のドキュメントを読み込みました")
return documents
def split_documents(documents):
"""ドキュメントをチャンクに分割"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
separators=["\n## ", "\n### ", "\n\n", "\n", " ", ""]
)
chunks = text_splitter.split_documents(documents)
print(f"合計{len(chunks)}個のチャンクを作成しました")
return chunks
def create_vectorstore(chunks, persist_dir: str):
"""ベクトルDBを作成"""
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
chunk_size=500
)
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=persist_dir,
collection_metadata={"hnsw:space": "cosine"}
)
print(f"ベクトルDB作成完了: {persist_dir}")
return vectorstore
def index_documents():
"""全インデキシングパイプライン"""
docs_dir = os.getenv("DOCS_DIR", "./documents")
persist_dir = os.getenv("CHROMA_PERSIST_DIR", "./chroma_db")
# 読み込み → チャンキング → エンベディング → 保存
documents = load_documents(docs_dir)
chunks = split_documents(documents)
vectorstore = create_vectorstore(chunks, persist_dir)
return vectorstore
if __name__ == "__main__":
index_documents()
# インデキシングの実行
python indexer.py
RAGチェーンの構築
# rag_chain.py
import os
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from dotenv import load_dotenv
load_dotenv()
class RAGChain:
def __init__(self):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.vectorstore = Chroma(
persist_directory=os.getenv("CHROMA_PERSIST_DIR", "./chroma_db"),
embedding_function=self.embeddings
)
self.retriever = self.vectorstore.as_retriever(
search_type="mmr", # Maximum Marginal Relevance
search_kwargs={
"k": 5,
"fetch_k": 20,
"lambda_mult": 0.7
}
)
self.llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.1,
max_tokens=2000
)
self.chain = self._build_chain()
def _build_chain(self):
"""RAGチェーンを構成"""
prompt = ChatPromptTemplate.from_messages([
("system", """あなたは社内ドキュメントベースのQ&Aアシスタントです。
以下のコンテキストに基づいて質問に回答してください。
ルール:
1. コンテキストにある情報のみを使用してください。
2. 確信がない場合は「関連ドキュメントが見つかりませんでした」と答えてください。
3. 回答に出典ドキュメントを含めてください。
4. コードやコマンドがある場合はコードブロックでフォーマットしてください。
コンテキスト:
{context}"""),
("human", "{question}")
])
def format_docs(docs):
formatted = []
for i, doc in enumerate(docs):
source = doc.metadata.get("source", "unknown")
formatted.append(f"[ドキュメント {i+1}] ({source})\n{doc.page_content}")
return "\n\n---\n\n".join(formatted)
chain = (
{"context": self.retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| self.llm
| StrOutputParser()
)
return chain
def ask(self, question: str) -> dict:
"""質問に回答"""
# 関連ドキュメントを検索
docs = self.retriever.invoke(question)
# LLM生成
answer = self.chain.invoke(question)
# 出典ドキュメント情報
sources = list(set(
doc.metadata.get("source", "unknown") for doc in docs
))
return {
"answer": answer,
"sources": sources,
"num_docs": len(docs)
}
def refresh_index(self):
"""インデックスの更新"""
from indexer import index_documents
self.vectorstore = index_documents()
self.retriever = self.vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 5, "fetch_k": 20, "lambda_mult": 0.7}
)
self.chain = self._build_chain()
Slack Bot連携
Slackアプリの設定
1. https://api.slack.com/apps で新しいアプリを作成
2. Socket Modeを有効化
3. Bot Token Scopesを追加:
- app_mentions:read
- chat:write
- im:history
- im:read
- im:write
4. Event Subscriptionsを有効化:
- app_mention
- message.im
5. ワークスペースにインストール
Slack Botの実装
# main.py
import os
import logging
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
from rag_chain import RAGChain
from dotenv import load_dotenv
load_dotenv()
logging.basicConfig(level=logging.INFO)
# Slack Appの初期化
app = App(token=os.environ["SLACK_BOT_TOKEN"])
# RAG Chainの初期化
rag = RAGChain()
@app.event("app_mention")
def handle_mention(event, say, client):
"""@メンションで質問を受ける"""
user = event["user"]
text = event["text"]
channel = event["channel"]
thread_ts = event.get("thread_ts", event["ts"])
# ボットメンションを除去
question = text.split(">", 1)[-1].strip()
if not question:
say(
text="質問を入力してください!例:`@DocBot デプロイ手順を教えて`",
thread_ts=thread_ts
)
return
# ローディングメッセージ
loading_msg = client.chat_postMessage(
channel=channel,
thread_ts=thread_ts,
text=":mag: ドキュメントを検索しています..."
)
try:
# RAGクエリ
result = rag.ask(question)
# レスポンスのフォーマット
response = f"<@{user}>\n\n{result['answer']}"
if result["sources"]:
sources_text = "\n".join(f"• `{s}`" for s in result["sources"])
response += f"\n\n:page_facing_up: *参考ドキュメント:*\n{sources_text}"
# ローディングメッセージを更新
client.chat_update(
channel=channel,
ts=loading_msg["ts"],
text=response
)
except Exception as e:
logging.error(f"RAG error: {e}")
client.chat_update(
channel=channel,
ts=loading_msg["ts"],
text=f"申し訳ございません。エラーが発生しました: {str(e)}"
)
@app.event("message")
def handle_dm(event, say):
"""DMで質問を受ける"""
if event.get("channel_type") != "im":
return
if event.get("bot_id"):
return
question = event["text"]
try:
result = rag.ask(question)
response = result["answer"]
if result["sources"]:
sources_text = "\n".join(f"• `{s}`" for s in result["sources"])
response += f"\n\n:page_facing_up: *参考ドキュメント:*\n{sources_text}"
say(text=response)
except Exception as e:
say(text=f"エラーが発生しました: {str(e)}")
@app.command("/docbot-reindex")
def handle_reindex(ack, say):
"""スラッシュコマンドでインデックスを更新"""
ack()
say("インデックスを更新しています... :hourglass_flowing_sand:")
try:
rag.refresh_index()
say("インデックスの更新が完了しました! :white_check_mark:")
except Exception as e:
say(f"インデックスの更新に失敗しました: {str(e)}")
if __name__ == "__main__":
handler = SocketModeHandler(app, os.environ["SLACK_APP_TOKEN"])
print("Slack RAG Bot started!")
handler.start()
Dockerデプロイ
# Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
# インデキシング後にボットを起動
CMD ["python", "main.py"]
# docker-compose.yml
version: '3.8'
services:
slack-rag-bot:
build: .
env_file: .env
volumes:
- ./documents:/app/documents
- ./chroma_db:/app/chroma_db
restart: unless-stopped
# ビルドと実行
docker compose up -d
# ログの確認
docker compose logs -f
パフォーマンス最適化
エンベディングキャッシュ
from langchain.storage import LocalFileStore
from langchain.embeddings import CacheBackedEmbeddings
store = LocalFileStore("./embedding_cache")
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=OpenAIEmbeddings(model="text-embedding-3-small"),
document_embedding_cache=store,
namespace="text-embedding-3-small"
)
会話履歴(スレッドコンテキスト)
from langchain.memory import ConversationBufferWindowMemory
# スレッドごとのメモリ管理
thread_memories = {}
def get_memory(thread_ts: str) -> ConversationBufferWindowMemory:
if thread_ts not in thread_memories:
thread_memories[thread_ts] = ConversationBufferWindowMemory(
k=5,
memory_key="chat_history",
return_messages=True
)
return thread_memories[thread_ts]
まとめ
Slack RAGチャットボットのキーポイント:
- ドキュメントチャンキング:RecursiveCharacterTextSplitterで意味単位の分割
- ベクトル検索:MMR(Maximum Marginal Relevance)で多様なドキュメント検索
- プロンプト:出典明記+不確実な場合は正直に答えるよう設計
- Slack連携:Socket Mode + app_mention/DMイベント処理
- 再インデキシング:スラッシュコマンドでドキュメント更新を反映
📝 クイズ(7問)
Q1. RAGのフルネームと核心的なアイデアは? Retrieval-Augmented Generation。外部知識を検索してLLMの生成に活用すること。
Q2. RecursiveCharacterTextSplitterのchunk_overlapの役割は? チャンク間に重複部分を設けてコンテキストの損失を防ぐこと。
Q3. MMR(Maximum Marginal Relevance)検索の利点は? 類似度が高いドキュメントだけを返すのではなく、多様性も考慮して重複を削減すること。
Q4. Slack Socket Modeの利点は? 公開URL/インバウンドポートなしでWebSocketを介してイベントを受信できること。
Q5. プロンプトで「コンテキストにある情報のみを使用してください」と明示する理由は? LLMのハルシネーションを防止し、ドキュメントベースの正確な回答を誘導するため。
Q6. thread_tsを使用する理由は? Slackスレッド内で会話コンテキストを維持するため。
Q7. エンベディングキャッシュの効果は? 同一ドキュメントへの繰り返しエンベディングAPI呼び出しを防止し、コストと時間を節約すること。