- Authors
- Name
Overview
Sparkはデータの入出力をディスクではなくメモリで行うため、中間結果をHDFS上に保存する必要がありません。そのためI/Oで大幅な時間短縮が可能で、最大100倍高速だと宣伝されています。spark3.3.1-cluster-overview
Sparkは以下の4種類のCluster Manager TYPEを提供しています。

この中から、既存のHadoopのYARNを活用する方法でSparkをインストールしてみます。
Install
Spark Standaloneで起動するには、すべてのノードにSparkをインストールする必要がありますが、Spark on YARNではクライアントとなる1台のノードにのみインストールすれば済みます。 インストール済みのHadoopバージョンは3.3.4、Sparkバージョンは3.3.1です。
DownLoad
筆者はNameNodeが動作しているノードにSparkのインストールを行いました。
wget https://dlcdn.apache.org/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz
tar -zxvf spark-3.3.1-bin-hadoop3.tgz
そして、適切な場所にバイナリファイルを移動します。筆者の場合は/usr/local/sparkに移動しました。
cp -R spark-3.3.1-bin-hadoop3 /usr/local/spark
Configuration設定
~/.bashrc
以下の内容を追加します。
export SPARK_HOME=/usr/local/spark
PATH=$PATH:$SPARK_HOME/bin
環境変数のリロードはsource ~/.bashrcで行います。
バイナリファイルをダウンロードすると、$SPARK_HOME/confの下に.templateで終わるファイルがあります。以下のようにコピーして設定します。
spark-env.sh
root@ubuntu01:/usr/local/spark/conf# ls
fairscheduler.xml.template log4j2.properties.template metrics.properties.template spark-defaults.conf.template spark-env.sh.template workers.template
root@ubuntu01:/usr/local/spark/conf# cp spark-env.sh.template spark-env.sh
以下のように追加します。
# Options read in any cluster manager using HDFS
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Options read in YARN client/cluster mode
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
spark-defaults.conf
spark.history.fs.logDirectory hdfs:///sparklog
spark.eventLog.dir hdfs:///sparklog
spark.eventLog.enabled true
spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider
Spark History Serverの起動
/usr/local/spark/sbin# ./start-history-server.sh
以下のように18080ポートでHistory Serverが実行されているか確認します。
pysparkの実行
円周率を求める以下の例題を実行して、SparkがYARNを通じて正常に動作するか確認します。
root@ubuntu01:/usr/local/spark/examples/src/main/python# spark-submit --master yarn --deploy-mode cluster pi.py
以下のような実行結果が表示されれば、正常にインストールされたと判断できます。
22/11/26 03:09:49 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/11/26 03:09:50 INFO DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at ubuntu01/192.168.219.101:8040
22/11/26 03:09:50 INFO Configuration: resource-types.xml not found
22/11/26 03:09:50 INFO ResourceUtils: Unable to find 'resource-types.xml'.
22/11/26 03:09:50 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
22/11/26 03:09:50 INFO Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead
22/11/26 03:09:50 INFO Client: Setting up container launch context for our AM
22/11/26 03:09:50 INFO Client: Setting up the launch environment for our AM container
22/11/26 03:09:50 INFO Client: Preparing resources for our AM container
22/11/26 03:09:50 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
22/11/26 03:09:51 INFO Client: Uploading resource file:/tmp/spark-817663b0-763a-4276-9323-06d7673fef50/__spark_libs__4960795851374146516.zip -> hdfs://ubuntu01:9000/user/root/.sparkStaging/application_1669137917003_0010/__spark_libs__4960795851374146516.zip
22/11/26 03:09:54 INFO Client: Uploading resource file:/usr/local/spark/examples/src/main/python/pi.py -> hdfs://ubuntu01:9000/user/root/.sparkStaging/application_1669137917003_0010/pi.py
22/11/26 03:09:54 INFO Client: Uploading resource file:/usr/local/spark/python/lib/pyspark.zip -> hdfs://ubuntu01:9000/user/root/.sparkStaging/application_1669137917003_0010/pyspark.zip
22/11/26 03:09:54 INFO Client: Uploading resource file:/usr/local/spark/python/lib/py4j-0.10.9.5-src.zip -> hdfs://ubuntu01:9000/user/root/.sparkStaging/application_1669137917003_0010/py4j-0.10.9.5-src.zip
22/11/26 03:09:54 INFO Client: Uploading resource file:/tmp/spark-817663b0-763a-4276-9323-06d7673fef50/__spark_conf__2594025362965367855.zip -> hdfs://ubuntu01:9000/user/root/.sparkStaging/application_1669137917003_0010/__spark_conf__.zip
22/11/26 03:09:54 INFO SecurityManager: Changing view acls to: root
22/11/26 03:09:54 INFO SecurityManager: Changing modify acls to: root
22/11/26 03:09:54 INFO SecurityManager: Changing view acls groups to:
22/11/26 03:09:54 INFO SecurityManager: Changing modify acls groups to:
22/11/26 03:09:54 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/11/26 03:09:54 INFO Client: Submitting application application_1669137917003_0010 to ResourceManager
22/11/26 03:09:54 INFO YarnClientImpl: Submitted application application_1669137917003_0010
22/11/26 03:09:55 INFO Client: Application report for application_1669137917003_0010 (state: ACCEPTED)
22/11/26 03:09:55 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1669432194364
final status: UNDEFINED
tracking URL: http://ubuntu01:8088/proxy/application_1669137917003_0010/
user: root
22/11/26 03:09:56 INFO Client: Application report for application_1669137917003_0010 (state: ACCEPTED)
22/11/26 03:09:57 INFO Client: Application report for application_1669137917003_0010 (state: ACCEPTED)
22/11/26 03:09:58 INFO Client: Application report for application_1669137917003_0010 (state: ACCEPTED)
22/11/26 03:09:59 INFO Client: Application report for application_1669137917003_0010 (state: ACCEPTED)
22/11/26 03:10:00 INFO Client: Application report for application_1669137917003_0010 (state: RUNNING)
22/11/26 03:10:00 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: ubuntu03
ApplicationMaster RPC port: 43259
queue: default
start time: 1669432194364
final status: UNDEFINED
tracking URL: http://ubuntu01:8088/proxy/application_1669137917003_0010/
user: root
22/11/26 03:10:01 INFO Client: Application report for application_1669137917003_0010 (state: RUNNING)
22/11/26 03:10:02 INFO Client: Application report for application_1669137917003_0010 (state: RUNNING)
22/11/26 03:10:03 INFO Client: Application report for application_1669137917003_0010 (state: RUNNING)
22/11/26 03:10:04 INFO Client: Application report for application_1669137917003_0010 (state: RUNNING)
22/11/26 03:10:05 INFO Client: Application report for application_1669137917003_0010 (state: RUNNING)
22/11/26 03:10:06 INFO Client: Application report for application_1669137917003_0010 (state: RUNNING)
22/11/26 03:10:07 INFO Client: Application report for application_1669137917003_0010 (state: RUNNING)
22/11/26 03:10:08 INFO Client: Application report for application_1669137917003_0010 (state: FINISHED)
22/11/26 03:10:08 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: ubuntu03
ApplicationMaster RPC port: 43259
queue: default
start time: 1669432194364
final status: SUCCEEDED
tracking URL: http://ubuntu01:8088/proxy/application_1669137917003_0010/
user: root
22/11/26 03:10:08 INFO ShutdownHookManager: Shutdown hook called
22/11/26 03:10:08 INFO ShutdownHookManager: Deleting directory /tmp/spark-467194a9-c6c1-4708-88aa-f66d15229dd6
22/11/26 03:10:08 INFO ShutdownHookManager: Deleting directory /tmp/spark-817663b0-763a-4276-9323-06d7673fef50
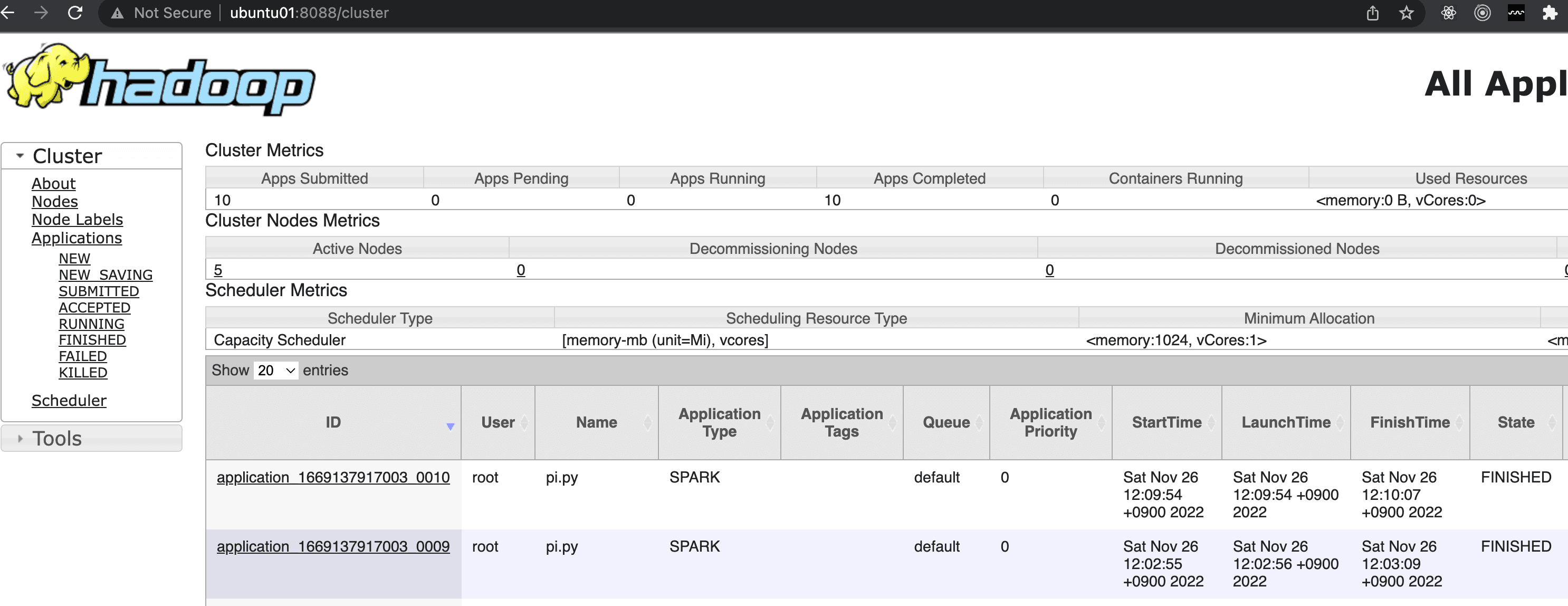
以下のように、このジョブについてSpark History ServerとResource Manager Web UIの両方で正常にジョブが送信されたことが確認できます。
Hive (MapReduce) と SparkSQL の比較
Hiveの場合、クエリをMapReduceで処理しますが、Sparkでも処理できます。https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Startedを参照してください。しかし、最近ではHive から Spark から YARNという構成よりも、Hiveを使わずにSparkSQL から YARNという構成で使用するのが主流のようです。
MovieLensデータのu_dataテーブルでselect movieid, avg(rating) as avg_rating from u_data group by movieid sort by avg_rating DESC;というクエリをHiveで実行し、メモリで実行されるSparkが、HDFSを使用するMapReduceと比較してどれだけ高速かを測定してみます。
Hive (MapReduce Engine)
Hiveの場合、33.699秒かかりました。
hive> select movieid, avg(rating) as avg_rating from u_data group by movieid sort by avg_rating DESC;
Time taken: 33.699 seconds, Fetched: 1682 row(s)
Spark SQL
preparation
Spark SQLを使用するには、Hiveインストール時と同様にmysql-connectorが必要です。mysql-connectorのインストール方法はリンクを参照してください。
その後、mysql-connector-java-*.jarを$SPARK_HOME/jars/配下に配置します。
pysparkの実行
$SPARK_HOME/bin/pysparkを実行した後、以下のコードを入力してみましょう。
from pyspark.sql import SparkSession
import time
start = time.time()
math.factorial(100000)
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
spark.sql("select movieid, avg(rating) as avg_rating from u_data group by movieid sort by avg_rating DESC").show()
end = time.time()
print(f"{end - start:.5f} sec")
実行にわずか約6秒しかかかりませんでした。驚くべき結果です。従来のMapReduceで実行されるHiveの33秒と比較して、大幅に高速化されたことがわかります。
6.07104 sec
Reference
- https://spark.apache.org/docs/latest/running-on-yarn.html
- https://www.youtube.com/watch?v=znBa13Earms
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=rix962&logNo=220835606224
- https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
- https://community.cloudera.com/t5/Support-Questions/Hive-on-Spark-Queries-are-not-working/td-p/58199
spark-submit --master yarn --deploy-mode cluster --num-executors 4 wordcount.py hdfs:///tmp/input/sample.txt