- Authors
- Name
Background
HBaseはHadoop上で動作するリアルタイムデータベースですが、リレーショナルDBのような高水準のDMLは提供しません。NoSQLであっても、パフォーマンスとスケーラビリティに焦点を当てた結果、非常にシンプルなAPIのみを開発者に提供しています。PUT、GET、SCAN、DELETE、INCREMENTとそれらから派生したいくつかの操作がすべてです。リレーショナルDBでよく使われるSecondary IndexやJOINは提供されず、Transactionも行単位でのみ提供されます。そのため、row-keyと呼ばれる唯一のキーの設計を一度間違えると、データの照会や集計の際にテーブル全体を走査する(Full Scan)必要が出てくる可能性があります。Full Scanを並列処理することも容易ではありません。シングルスレッドで実行する場合、データサイズが小さければFull Scanでも問題ありませんが、データサイズがTBレベルまで増加すると数日かかることもあります。良い方法ではありません。
幸いなことに、このFull Scanを高速に行う方法があります。それはMapReduceを使用することです。HBaseはHadoopのMapReduceのデータソースとして使用できます。MapReduceは古い技術ではありますが、バッチ処理用としての利用には問題がなく、HBase公式ドキュメントでもHBaseとMapReduceの連携方法を案内しています。
Goal
MapReduceプログラムの中で最もシンプルな、テーブルの行数を計算するプログラムを作成します。
Steps
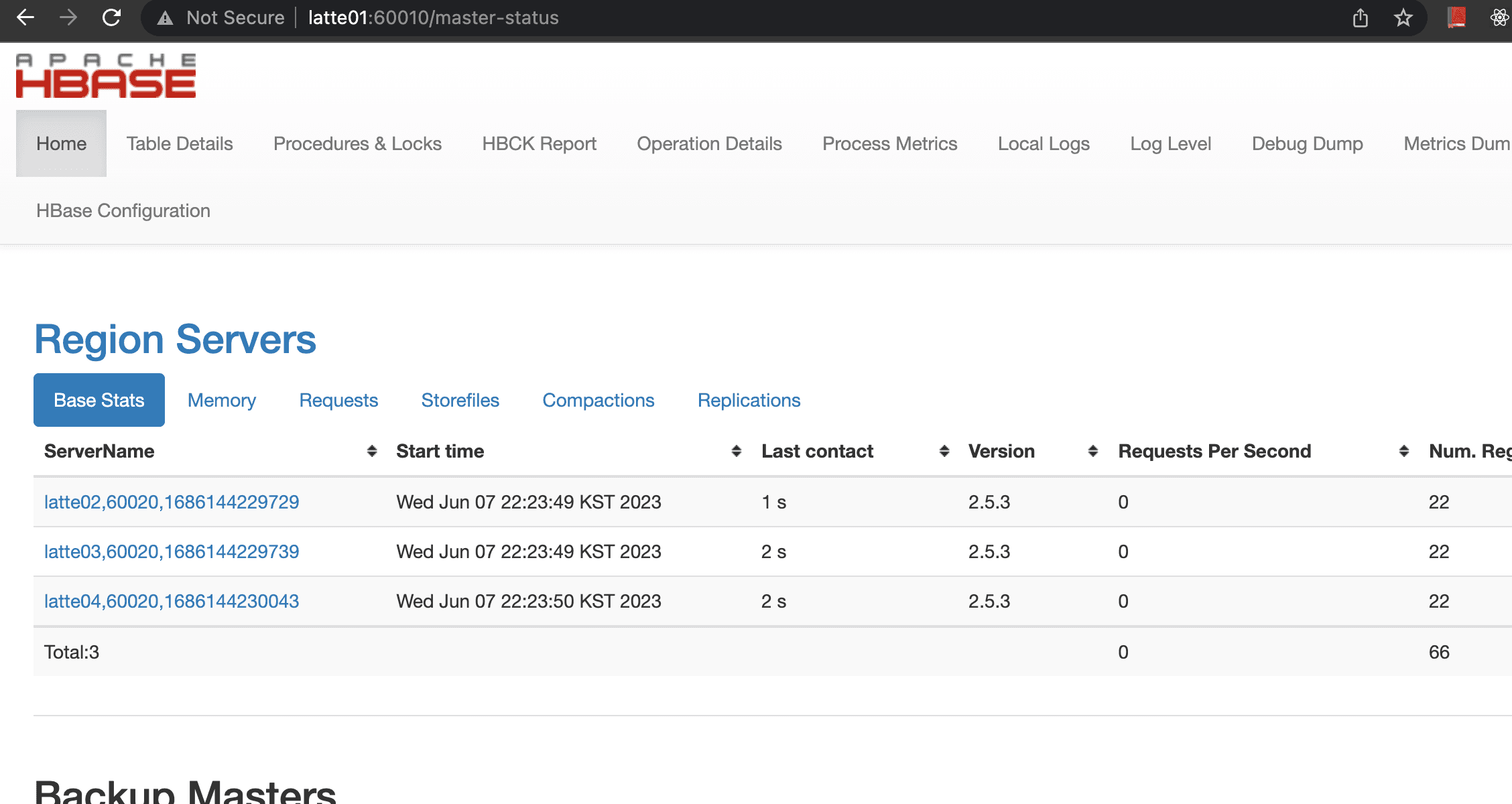
HBase Cluster
当然ながら、HBaseクラスタが必要です。また、MapReduceジョブを実行するためのYARNコンポーネントも必要です。HBaseのインストール方法はこちらを参照してください。
現在のクラスタは、マスターノード1台、ワーカーノード3台で構成されています。
開発環境の構築
IntelliJでNew Projectを作成します。
MapReduceプログラムの作成
MapReduceプログラムを作成するには、一般的にDriver、Mapper、Reducerの3つが必要ですが、Row Counterプログラムの場合はReducerが不要なため、DriverとMapperのみを作成します。
Driverの作成
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;
import java.io.IOException;
public class RowCounterJob {
private static final String zookeeper_quorum = "latte01,latte02,latte03";
private static final String zookeeper_port = "2181";
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// HBase関連のconfig登録
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", zookeeper_quorum);
config.set("hbase.zookeeper.property.clientPort", zookeeper_port);
// Job作成
Job job = new Job(config, "RowCounter");
job.setJarByClass(RowCounterJob.class);
Scan scan = new Scan();
// Full Scanを行う際、scanオブジェクトを以下のように設定する必要があります。
scan.setCaching(500);
scan.setCacheBlocks(false);
// Table Mapper登録
TableMapReduceUtil.initTableMapperJob(
"usertable", // テーブル名
scan,
RowCounterMapper.class, // Mapper Classの登録
Text.class,
IntWritable.class,
job
);
job.setOutputFormatClass(NullOutputFormat.class);
job.setNumReduceTasks(1);
// jobの送信
boolean b = job.waitForCompletion(true);
if(!b){
throw new IOException("error with job");
}
}
}
Mapperの作成
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class RowCounterMapper extends TableMapper<Text, IntWritable> {
public enum Counters {ROWS}
@Override
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException {
context.getCounter(Counters.ROWS).increment(1);
}
}
必要なライブラリ
現在構築されたHadoopとHBaseのバージョンを確認します。
HBase: 2.5.3 Hadoop: 3.3.2
HBaseのバージョンによって必要なライブラリ名が異なります。
hbase-clientとhbase-mapreduceが必要です。
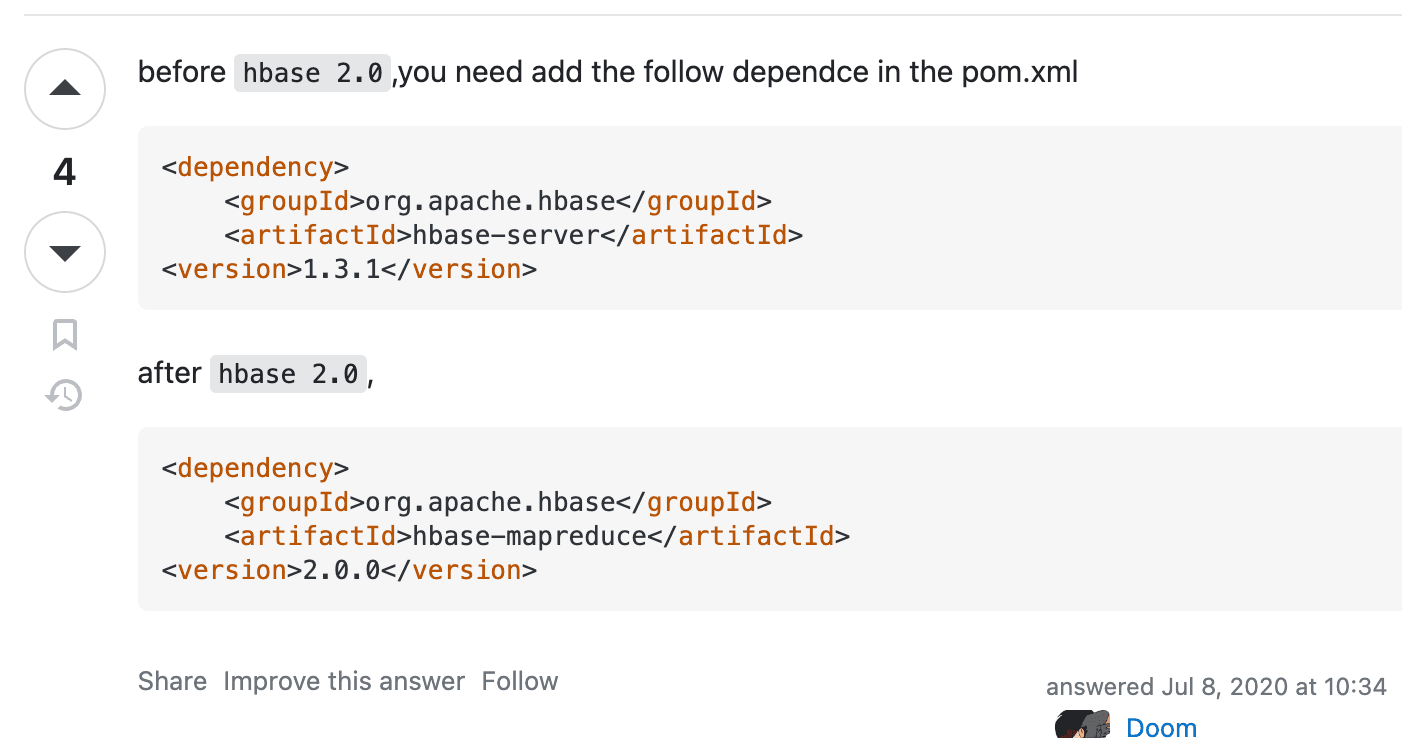
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.5.3</version>
</dependency>
</dependencies>
MapReduce JARのビルドおよび生成方法
MapReduceジョブを実行するには、必要なすべてのdependencyが含まれた1つのJARファイルを生成する必要があります。 Mavenのmaven-assembly-pluginを使用してもよいですが、便宜上IntelliJが提供するArtifacts機能を使用します。
左上のFileからProject StructureからArtifactsからADDからJARからFrom Modules with dependenciesをクリックします。
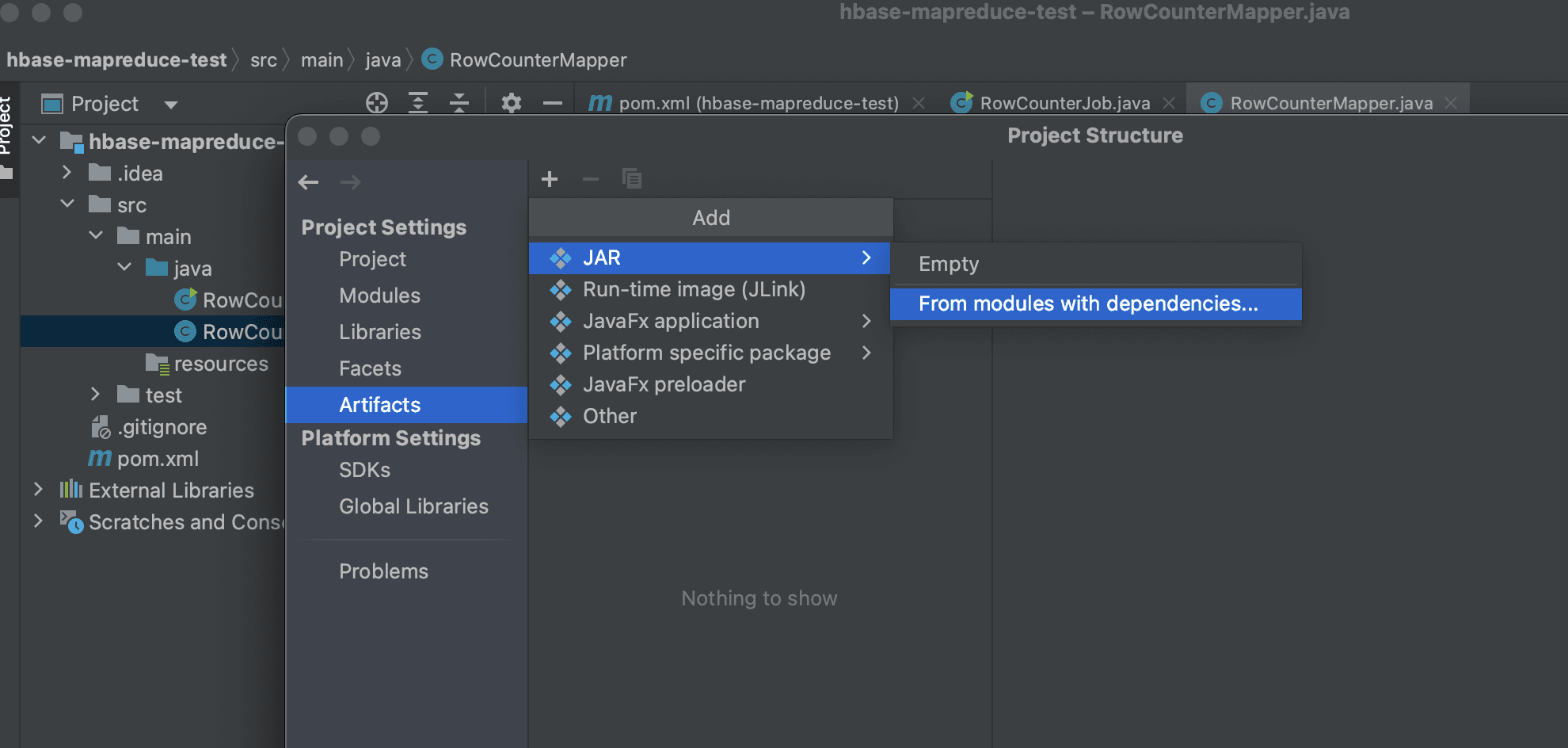
次に、Main Classを見つけて「extract to the target JAR」を選択し、新しいartifactを生成します。
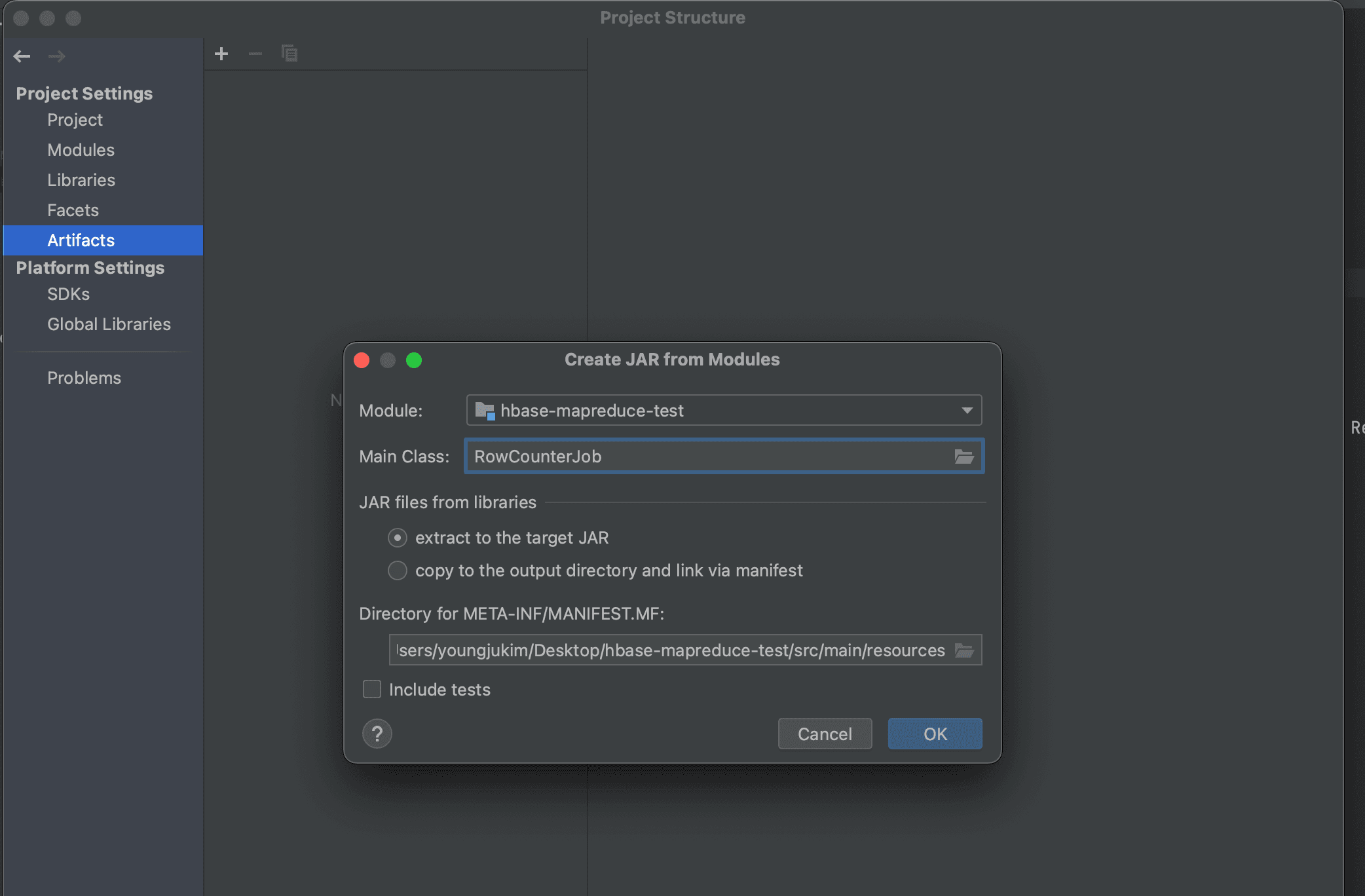
上部のBuildからBuild Artifactを押してビルドを進めます。
プロジェクトルートディレクトリのOutからartifacts配下に移動すると、JARファイルが生成されていることを確認できます。
JARファイルの実行方法
該当ファイルをHBaseとYARNを実行できるサーバーに転送します。筆者はローカルPCのpublic keyをlatte01のauthorized_keysに登録してあったため、以下のscpコマンドでファイルを転送できました。
scp hbase-mapreduce-test.jar latte01:<path you want to move>
MapReduceジョブの送信方法。
HADOOP_CLASSPATH=`hbase classpath` hadoop jar hbase-mapreduce-test.jar RowCounterJob
上記のコマンドで実行した際、以下のエラーメッセージが発生し、ジョブが送信されませんでした。
Exception in thread "main" java.lang.IllegalAccessError: class org.apache.hadoop.hdfs.web.HftpFileSystem cannot access its superinterface org.apache.hadoop.hdfs.web.TokenAspect$TokenManagementDelegator
https://stackoverflow.com/questions/62880009/error-through-remote-spark-job-java-lang-illegalaccesserror-class-org-apache-h によると、fat JARを作成する際にhadoop-hdfsライブラリが問題を引き起こすようなので、artifact生成時に該当ライブラリを削除しました。
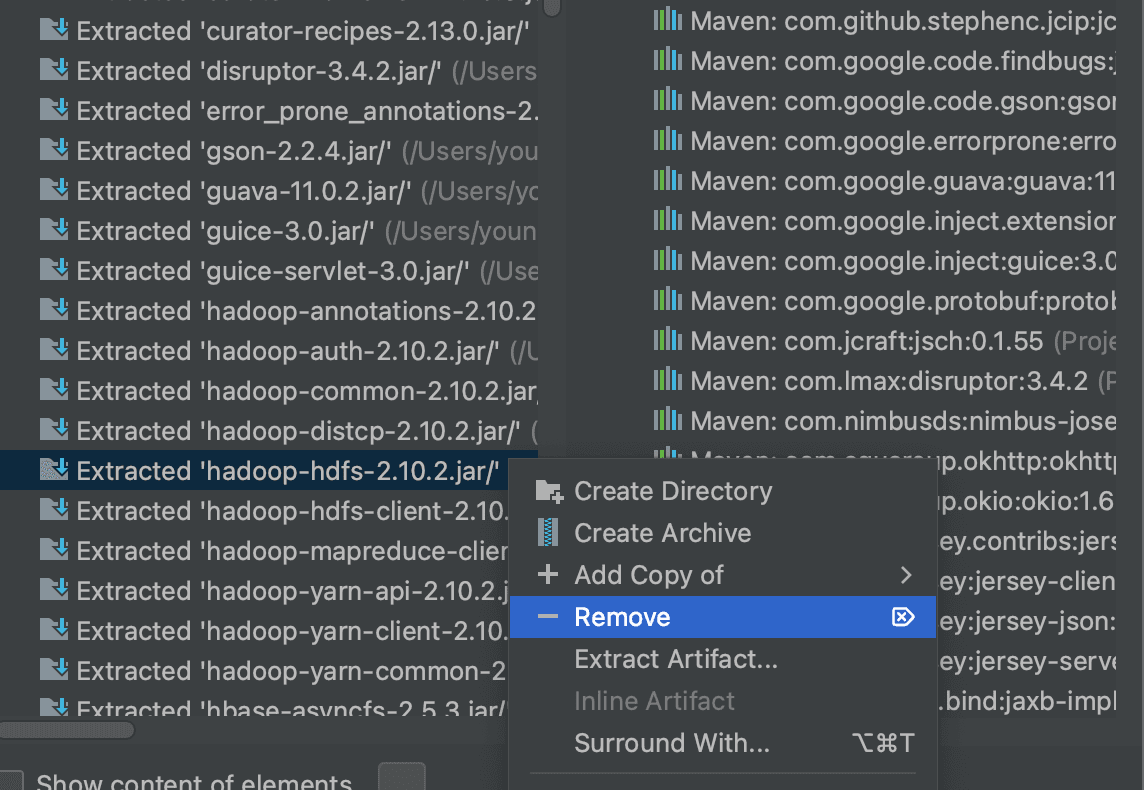
同じエラーが発生したため、HBaseに標準で含まれているrow counterが正常に動作するか確認してみました。
hbase org.apache.hadoop.hbase.mapreduce.RowCounter <table name>
そもそもYARNクラスタに問題があったようです。
HDFS上に/user/hdfs、/user/hbase、/user/rootディレクトリを作成します。
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hdfs
hdfs dfs -mkdir /user/hbase
hdfs dfs -mkdir /user/root
hdfs dfs -chown hbase:supergroup /user/hbase
hdfs dfs -chown hdfs:supergroup /user/hdfs
userディレクトリを作成しても、以下のエラーが発生しました。
023-06-10 16:11:13,539 ERROR [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Error starting MRAppMaster
java.lang.ClassCastException: org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$GetFileInfoRequestProto cannot be cast to com.google.protobuf.Message
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
https://ngela.tistory.com/66 によると、Hadoopのバージョンによってprotobufが異なることで発生する問題とのことです。
HadoopとHBaseをバージョンに合わせて再インストールし、再度試みます。
HBase: 2.5.3 Hadoop: 2.10.2 Zookeeper: 3.5.7
Hadoop 2.10.2再インストール時のconfig
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://latte01:9000</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/dn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///dfs/sn</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
</configuration>
export HADOOP_IDENT_STRING=$USER
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>latte01:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>latte01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>latte01:8040</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///dfs/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///dfs/yarn/logs</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
latte02
latte03
latte04
NameNodeのフォーマット後、HDFSを起動
NameNodeで以下を実行します。
hadoop namenode -format
Hadoop、YARNコンポーネントを起動します。
start-all.sh
NameNodeとResource Managerが正常に起動したことを確認しました。
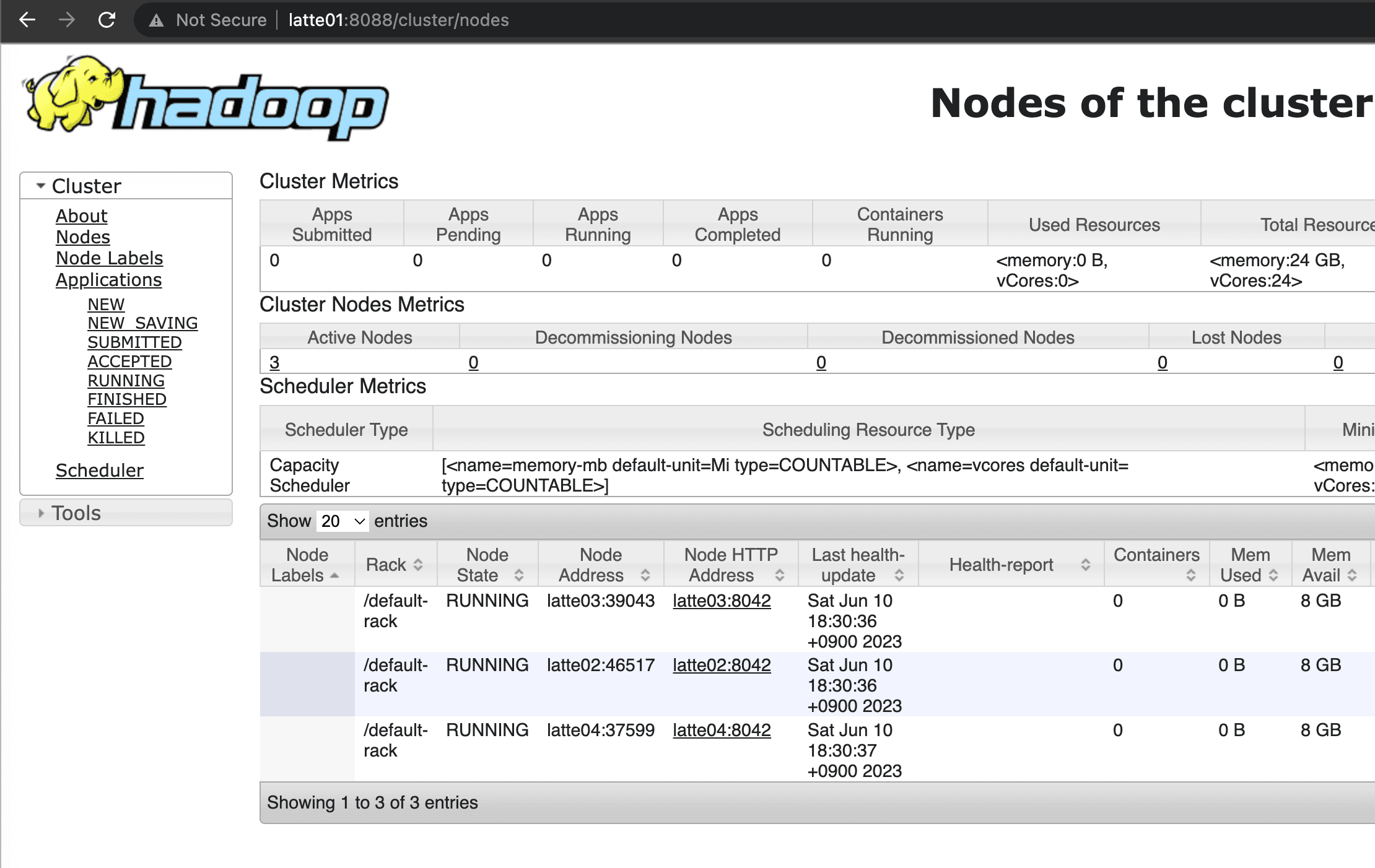
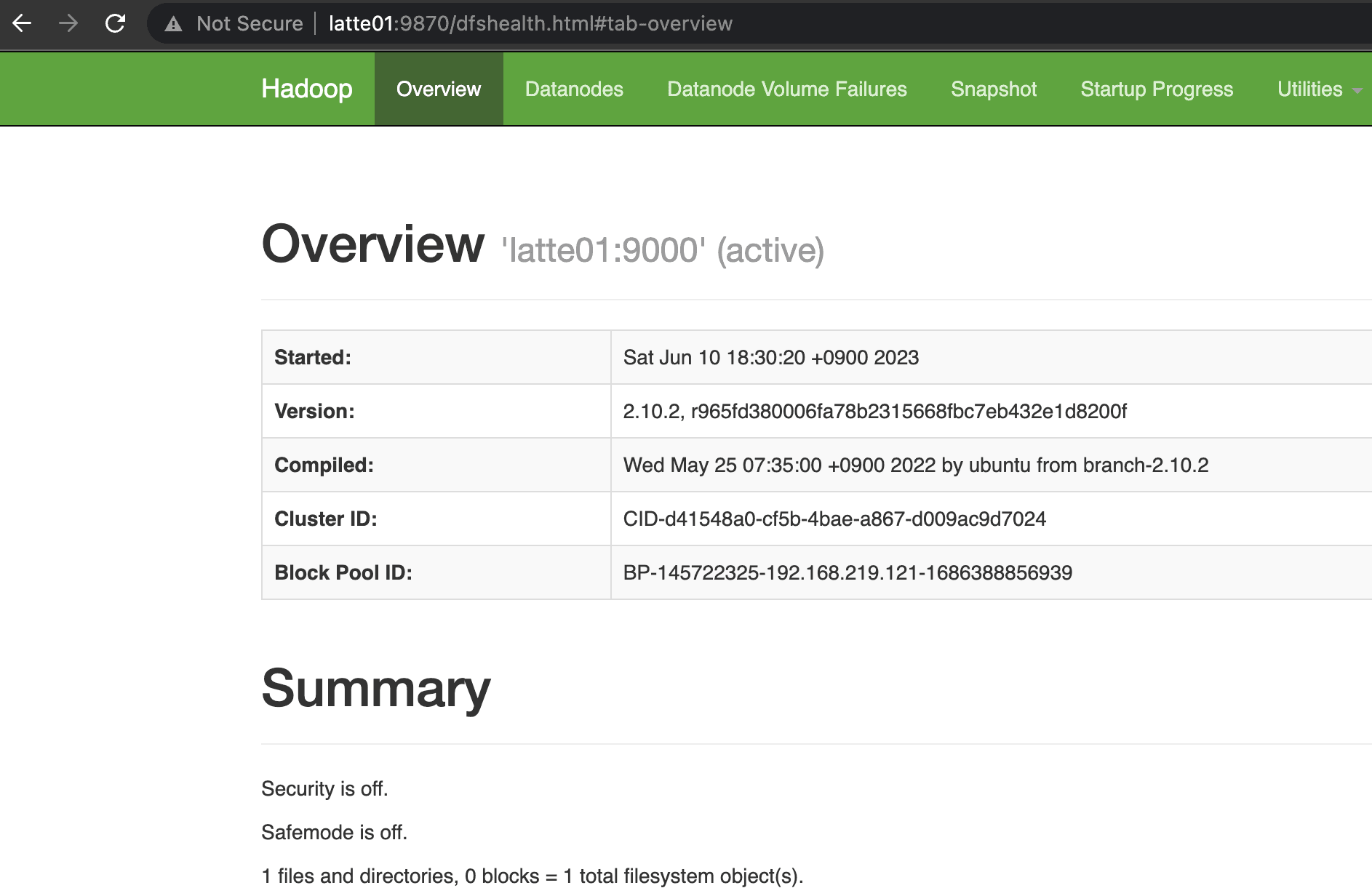
HBaseを起動します。
HBaseの起動
start-hbase.sh
YCSBのダウンロードおよび実行
curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gz
tar xfvz ycsb-0.17.0.tar.gz
cd ycsb-0.17.0
mkdir latte_hbase
vim hbase-site.xml
vim testoption
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://latte01:9000/hbase</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.regionserver.info.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hbase.regionserver.port</name>
<value>60020</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>60030</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>latte01,latte02,latte03</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<property>
<name>hbase.backup.enable</name>
<value>true</value>
</property>
<property>
<name>hbase.master.logcleaner.plugins</name>
<value>org.apache.hadoop.hbase.backup.master.BackupLogCleaner</value>
</property>
</configuration>
recordcount=10000000
operationcount=1000000
HBase shellに接続してusertableを作成します。
hbase(main):001:0> n_splits = 30
# HBase recommends (10 * number of regionservers)
hbase(main):002:0> create 'usertable', 'family', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}}
bin/ycsb load hbase20 -P workloads/workloada -P latte_hbase/testoptions -cp latte_hbase/ -p table=usertable -p columnfamily=family -p recordcount=10000000 -p operationcount=1000000 -threads 10
リクエスト数が1K近くまで増加したことを確認できます。
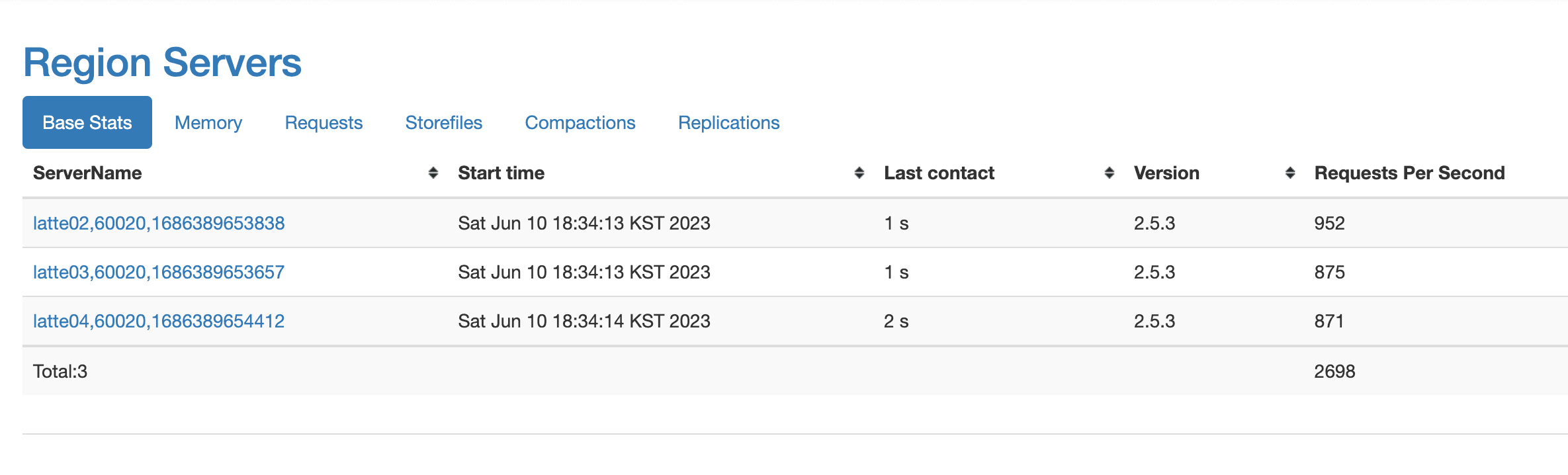
再度Row Count MapReduceを実行
hbase org.apache.hadoop.hbase.mapreduce.RowCounter usertable
MapReduceジョブが正常に実行されました。
2023-06-10 19:13:18,891 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1643)) - Job job_1686391929383_0001 running in uber mode : false
2023-06-10 19:13:18,894 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 0% reduce 0%
2023-06-10 19:13:51,888 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 6% reduce 0%
2023-06-10 19:13:52,948 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 16% reduce 0%
2023-06-10 19:13:53,966 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 26% reduce 0%
2023-06-10 19:13:59,063 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 35% reduce 0%
2023-06-10 19:14:00,097 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 39% reduce 0%
2023-06-10 19:14:01,118 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 52% reduce 0%
HBaseCounters
BYTES_IN_REMOTE_RESULTS=14106802
BYTES_IN_RESULTS=59441193
MILLIS_BETWEEN_NEXTS=282081
NOT_SERVING_REGION_EXCEPTION=0
REGIONS_SCANNED=31
REMOTE_RPC_CALLS=22
REMOTE_RPC_RETRIES=0
ROWS_FILTERED=44
ROWS_SCANNED=374127
RPC_CALLS=88
RPC_RETRIES=0
org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper$Counters
ROWS=374127
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
374,127個の行があることを確認しました。
自作のrow counter MapReduceを実行します。
hadoop jar hbase-mapreduce-test.jar RowCounterJob
以下のように同じ結果が出力されました。
23/06/10 19:40:03 INFO mapreduce.Job: map 87% reduce 0%
23/06/10 19:40:04 INFO mapreduce.Job: map 94% reduce 0%
23/06/10 19:40:05 INFO mapreduce.Job: map 97% reduce 0%
23/06/10 19:40:06 INFO mapreduce.Job: map 100% reduce 0%
RowCounterMapper$Counters
ROWS=374127
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0