- Authors
- Name
Overview
HBaseは分散処理のために、1つのテーブルをregionという単位で複数に分割して保存・管理します。 1つのRegionから始まり、リージョンのサイズが大きくなるにつれて、大きなリージョンは自動的にSplitされ、2つのregionに分割されます。 しかし、このsplit処理には大きなコストがかかります。 そのため、初期データが多いと判断される場合は、テーブル作成時にリージョンを事前に分割しておくことで、クラスタへの負荷を軽減できます。
では、どのような基準でテーブルをsplitすればよいのでしょうか?おそらく正解はrow-keyの設計によって異なるでしょう。 rowkeyの範囲が1xxxxxxから9xxxxxxであることが事前にわかっている場合、prefixが1から9のregionに事前分割するのが良いでしょう。
一般的な状況でよく使われるrowkeyパターンにも汎用的に使える3つの方法を紹介します。
PreSplit方法
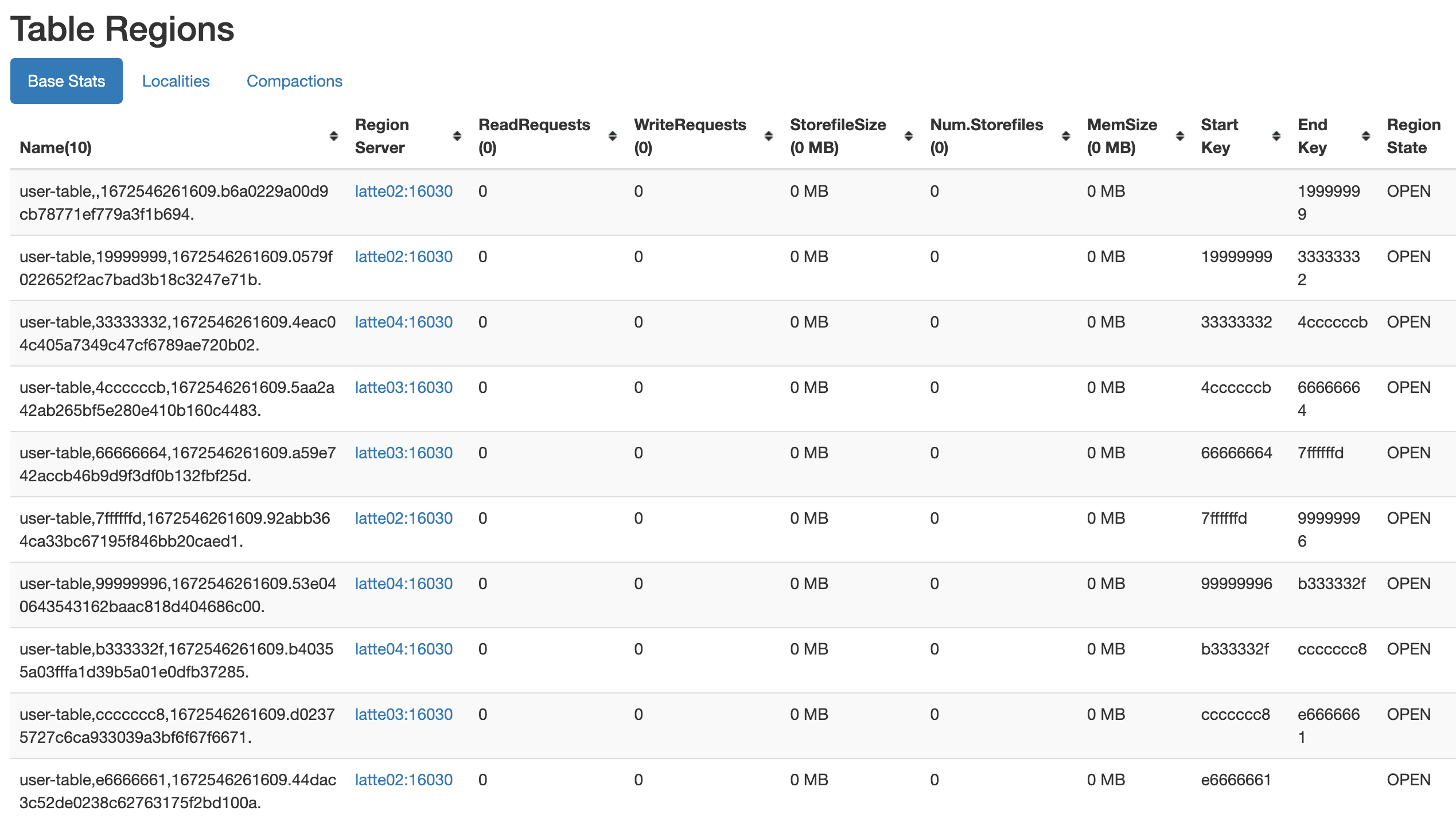
- HexStringSplit
以下のように、テーブル作成時にsplitアルゴリズムとしてHexStringSplitを選択すると、HexString[1-9a-z]を基準にregionをsplitして生成します。
create 'user-table', 'cf', {NUMREGIONS =>10, SPLITALGO => 'HexStringSplit'}
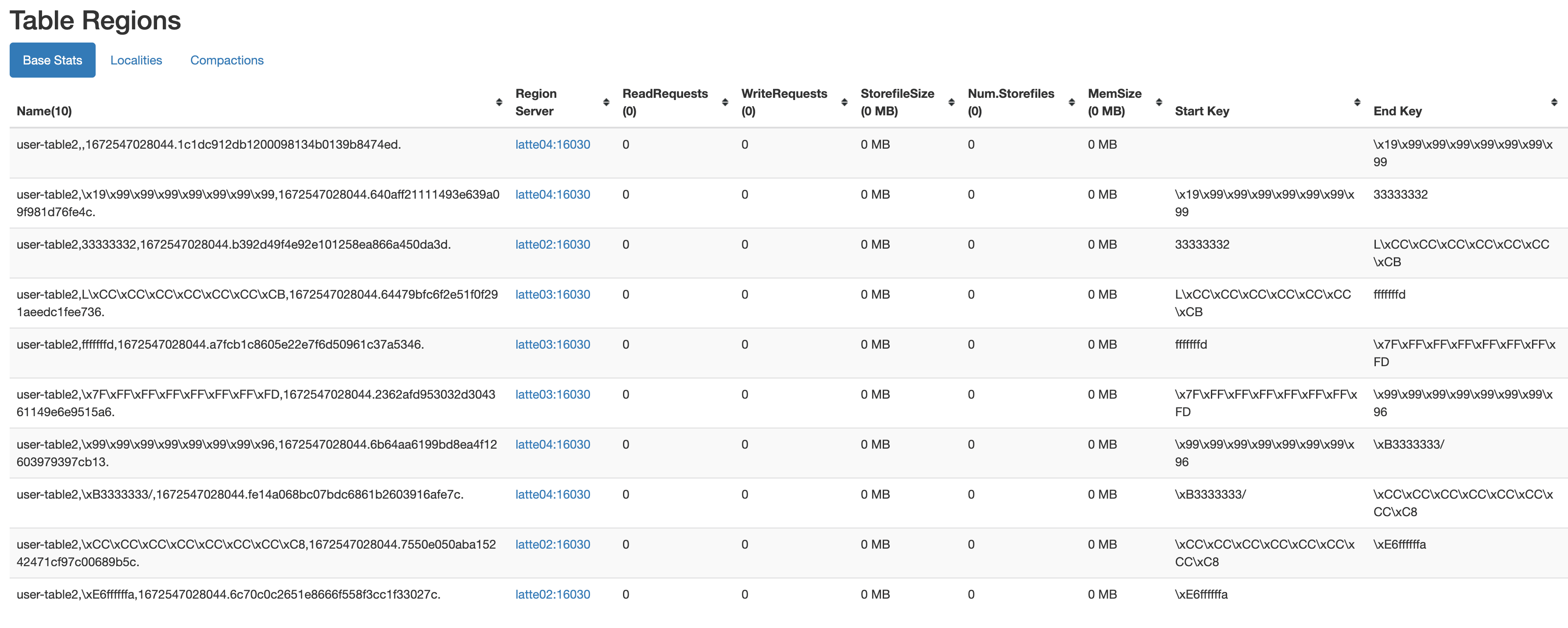
- UniformSplit
UniformSplitオプションも存在します。テーブルをrandom bytes keysで分割する方式で、regionは以下のように生成されます。
create 'user-table2', 'cf', {NUMREGIONS =>10, SPLITALGO => 'UniformSplit'}
- Custom Split
HBaseがデフォルトで提供するsplitアルゴリズムの代わりに、split関数を設定してリージョンを事前分割することも可能です。 例えば、データがすべてuser#xxxxというrowkeyを持っており、user#というprefixを先頭に付ける必要がある場合、hbase shellで以下のようにテーブルを作成できます。
n_splits = 10
create 'usertable', 'family', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}}
Reference
以上、HBase Tableをpresplitする3つの方法についての投稿を終わります。