- Authors
- Name
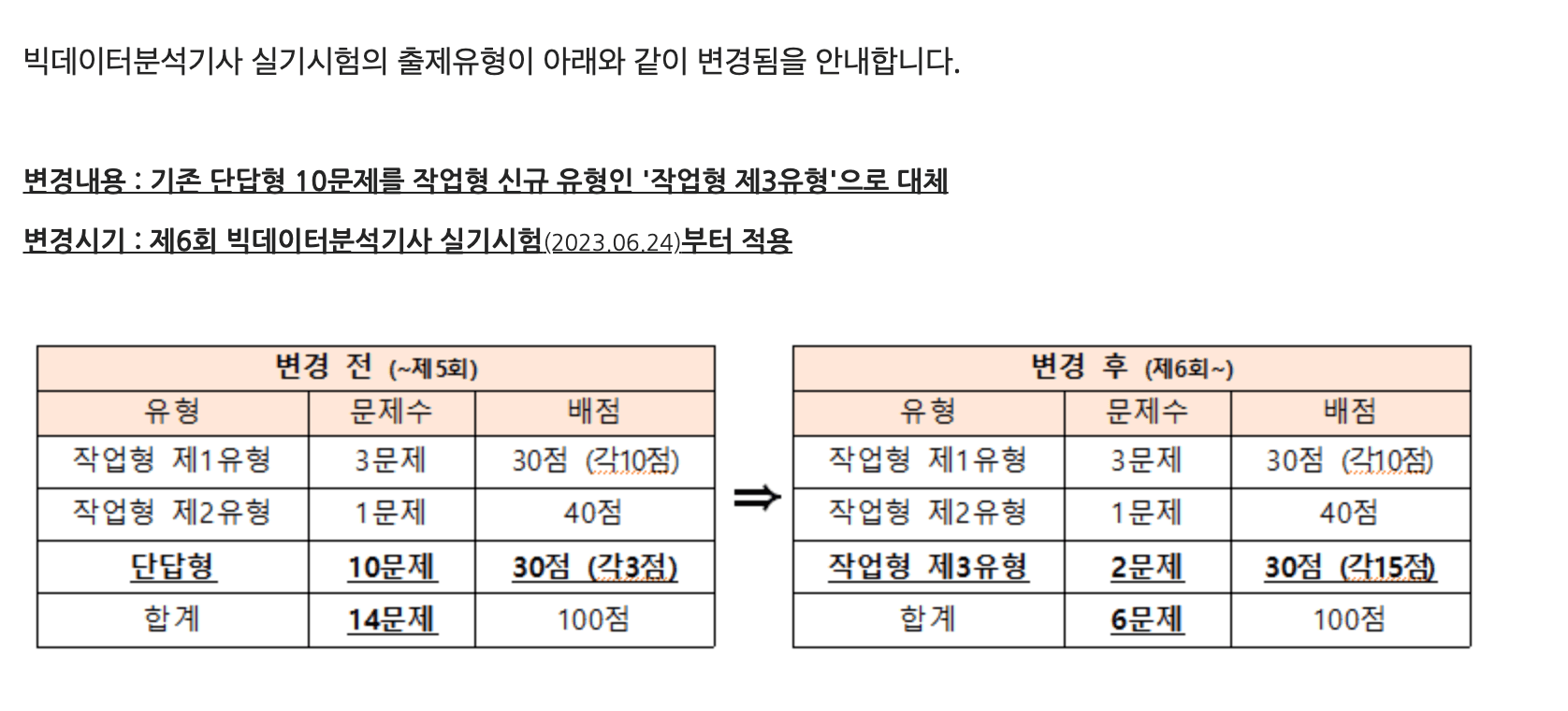
2023年6月24日に行われるビッグデータ分析技師第6回実技試験の準備で勉強した内容を整理しようと思う。今回の第6回試験では、既存の短答型問題が削除され、作業型3類型が追加された。機械学習から手を離して2年近くになるため、一度整理しようと思う。1類型と2類型はパターンが既に決まっているのでそれほど難しくないと思われるが、3類型は統計的な知識も問われるため難易度が高いと見込まれる。
実技試験の準備は退勤後別のことのYouTube動画と、この方が管理されているKaggleページに掲載されている過去問題復元問題を多く参考にし、大変助けになった。
作業型1類型
データの基礎操作能力を問うため、他の類型に比べて相対的に易しいが、IDEが提供されないため、ライブラリの使い方やDataFrame構文は一度整理しておく必要がありそうだ。既存の過去問で必要だったコマンドを整理する。
# csvデータを読み込む時
import pandas as pd
train = pd.read_csv("data/train .csv")
# データの基礎統計量確認
train.head() # 一部のデータのみ確認する時
train.describe() # 平均、標準偏差、四分位値を確認
train.describe(include="object") # 名義型(カテゴリカル)変数の基礎データ確認(この時trainの名義型変数のunique値とtestの名義型変数のunique値が同一か確認する必要がある。もし異なる場合、Label Encoding作業時にtrainとtestデータを結合してencodingを行う必要がある。)
train.isnull().sum() # 欠損値確認
# minmax scalerを直接実装
def minmax(data):
data = (data-min(data))/(max(data)- min(data))
return data
# qsec数値変数にminmax scalerを適用する場合、
train['qsec'] = minmax(train['qsec'])
# sklearn minmax scalerを利用
from sklearn.preprocessing import minmax_scale
qsec_scaled = minmax_scale(train['scale'])
# 'qsec'が0.5以上の行の数
sum(qsec_scaled >0.5) # Trueの数の合計
len(train[qsec_scaled >0.5]) # データの長さの合計
# ageカラムの標準偏差を求める
age_std = train['age'].std()
# f1カラムの欠損値を中央値で補間
train['f1'] = train['f1'].fillna(train['f1'].median())
# 先頭70%のデータのみ使用
df = df.iloc[:int(len(df)*0.7),:]
# カラムfilter条件複数
# ageカラムの異常値の合計。平均から「標準偏差 * 1.5」を超える領域を異常値と判断。
age = train['age']
age_outliers = age[ ((age < age.mean()-age.std()*1.5) | (age > age.mean()+age.std()*1.5))]
age_outliers.sum()
# indexベースのsort
train.sort_index(ascending=True) # 昇順
train.sort_index(ascending=False) # 降順
# valueベースのsort。ageを基準に降順ソート
sorted_train = train.sort_values(by=['age'], ascending=False)
# data frameをilocでアクセスする。
# 先頭10行の最後のカラムを、その10行の'f5'カラムの最小値で更新
df.iloc[:10, -1] = df['f5'][:10].min()
# ageカラムの第3四分位数と第1四分位数の差を絶対値で求め、小数点を切り捨てて整数で出力
ans = int(abs(df['age'].quantile(0.25) - df['age'].quantile(0.75)))
# カラムの型変更
submission['Segmentation'] = submission['Segmentation'].astype(int)
作業型2類型
作業型2類型はsupervised learningが出題され、ClassificationまたはRegressionタスクが出題される。やや面倒な点は、Featureに数値型(Numerical)変数と名義型(Categorical)変数が混在しているため、前処理で適切に処理してからモデルを学習させることが核心だ。性能を高めるためにはHyper Parameterのチューニングや異常値・欠損値の処理を行えばよい。(時間に余裕がある時のオプションのようだ。)結果物の提出時は、指定されたフォーマット通りに正しく合わせて提出することが重要だ。数値変数に対するスケーリングが不要で性能も準優秀なツリーベースのModel(RandomForest)を選択することが時間節約に有利だと思われる。
作業型2類型を解決する全体的なタスクは以下の通りだ。
- データEDA(変数type確認、基礎統計量確認、異常値や欠損値確認、target変数確認)
- データ前処理(名義型変数エンコーディング、欠損値処理、train/validデータセット分離)
- モデル作成及び学習/評価
- testデータの解答提出
# EDA
import pandas as pd
# データ読み込み
df = pd.read_csv("train.csv")
# データの次元確認
print(df.shape)
# 欠損値確認
print(df.isnull().sum())
# 基礎統計量確認
print(df.describe())
# データ前処理
df['age'] = df['age'].fillna(df['age'].median())
# データからtargetカラムを抽出
target = df.pop('target')
# Label Encoding(カテゴリ変数のラベルエンコーディング)
from sklearn.preprocessing import LabelEncoder
cols = df['aa', 'bb'] # カテゴリ変数
for col in cols:
le = LabelEncoder()
df[col] = le.fit_transform(df[col])
X_test[col] = le.transform(X_test[col])
print(df.head())
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(df, target)
print(model.score(df, target))
predictions = model.predict_proba(X_test)
# score処理指標を確実に把握しておくこと。
作業型3類型
作業型3類型の場合、どのような問題が出るか予想できなかったためリサーチを行った。YouTubeの「賢い統計生活」さんがアップされた動画を基に、以下の統計指標をPythonで実装する方法を暗記して臨もうと思う。
- Z検定
- T検定
- 1標本
- 2標本
- 2群の分散が等しい場合
- 2群の分散が異なる場合
- 対応のあるt検定
- カイ二乗検定
- ANOVA
import pandas as pd
from scipy import stats
a = pd.read_csv('data/blood_pressure.csv', index_col=0)
# print(a.shape)
# print(a.head())
a['diff'] = a['bp_after'] - a['bp_before']
#1
print(round(a['diff'].mean(),2))
#2
st , pv = stats.ttest_rel(a['bp_after'], a['bp_before'], alternative='less')
print(round(st,4))
#3
print(round(pv,4))