Split View: block based file system 이란? HDFS block file system.
block based file system 이란? HDFS block file system.
파일과 Block
우리가 일반적으로 사용하는 컴퓨터의 경우, 하나의 파일은 여러개의 블록으로 저장되고, 블록의 크기는 대부분 (운영체제나 설정에 따라 다를수 있지만) 512bytes 이다. 예를 들어 1MB의 파일을 저장한다고 하면 약 20개의 512 bytes의 블록에 나뉘어 저장되는 것이다.
이 블록크기가 너무 작아지면, 블록의 갯수가 많아져 메타데이터 오버헤드가 증가하게 되고, 블록의 크기가 너무 커지게 되면 공간 낭비의 위험이 증가합니다. 예를 들어 블록크기가 128MB라고 한다면, 1MB 짜리 파일을 저장하든, 5MB파일을 저장하든 상관없이 128MB를 블록을 할당해야하기 때문에 그 파일을 저장한 공간 외의 다른 공간을 사용하지 못합니다.
Block File System 의 장점
-
간결한 메타데이터: 각 블록의 크기가 고정되어 있기 때문에 파일 메타데이터에서 각 블록에 대한 위치와 크기를 명시적으로 저장할 필요가 없습니다. 이로 인해 메타데이터의 복잡성이 감소합니다.
-
효율적인 디스크 사용: 블록을 고정된 크기로 나누면 디스크의 공간 배치를 최적화하고, 디스크의 빈 공간을 최소화할 수 있습니다. 이로 인해 디스크의 사용률이 향상됩니다.
-
빠른 임의 접근: 블록 기반의 접근 방식은 임의의 위치에서 데이터에 접근하는 것을 용이하게 합니다. 특정 블록을 찾기 위해 필요한 계산이 간단하므로, 임의 접근 성능이 향상됩니다.
-
강력한 내결함성: 일부 블록 파일 시스템은 추가적인 오류 검출 및 복구 메커니즘이 블록 수준에서 제공됩니다. 이러한 메커니즘은 각 블록의 무결성을 확보하고, 오류가 발생할 경우 해당 블록만 복구하도록 도와줍니다.
-
효율적인 캐시 및 버퍼 관리: 블록을 고정된 크기로 관리하면, 시스템의 캐시와 버퍼 관리를 최적화할 수 있습니다. 이는 데이터 읽기 및 쓰기 작업의 성능을 향상시킵니다.
-
파일 크기의 동적 확장: 블록 기반의 파일 시스템은 필요에 따라 추가적인 블록을 할당하거나 반환하여 파일의 크기를 동적으로 확장하거나 축소할 수 있습니다.
-
데이터 조각화 최소화: 파일을 일정한 크기의 블록으로 나누면, 디스크상에서 파일의 조각화를 줄일 수 있습니다. 따라서 연속적인 디스크 영역에 데이터를 저장하고 읽어올 수 있어 성능이 향상됩니다.
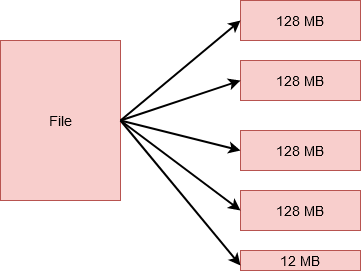
HDFS 블록 사이즈 128MB
HDFS(Hadoop File System)는 default로 128MB라는 훨씬 큰 크기의 블록사이즈를 가집니다. 이는 하둡이 태생적으로 대용량 데이터를 처리하도록 설계되었기 때문에 Random 처리보다는 스트리밍 처리를 위해 최적화 되었기 때문입니다. 또한 블록크기가 커지면 그만큼 Meta데이터의 크기도 작아지고, 이는 네임노드의 오버헤드를 감소시키기 때문에 관리측면에서 유리합니다.
Hadoop 네임노드의 경우 일반적으로 100만개의 블록을 저장할 때 1GB의 Heap Memory를 사용한다고 합니다.
What is a Block-Based File System? HDFS Block File System.
Files and Blocks
On a typical computer, a single file is stored across multiple blocks, and the block size is usually 512 bytes (though it may vary depending on the operating system or configuration). For example, when storing a 1MB file, it would be divided and stored across approximately 20 blocks of 512 bytes each.
If the block size is too small, the number of blocks increases, leading to greater metadata overhead. On the other hand, if the block size is too large, there is an increased risk of wasted space. For instance, if the block size is 128MB, then regardless of whether you are storing a 1MB file or a 5MB file, a 128MB block must be allocated, and the remaining space in that block cannot be used for other data.
Advantages of Block File Systems
-
Concise Metadata: Since each block has a fixed size, there is no need to explicitly store the location and size of each block in the file metadata. This reduces the complexity of the metadata.
-
Efficient Disk Usage: Dividing data into fixed-size blocks optimizes disk space allocation and minimizes free space on the disk, improving overall disk utilization.
-
Fast Random Access: Block-based access makes it easier to access data at arbitrary locations. Since the calculation needed to locate a specific block is straightforward, random access performance is improved.
-
Strong Fault Tolerance: Some block file systems provide additional error detection and recovery mechanisms at the block level. These mechanisms help ensure the integrity of each block and allow recovery of only the affected block when errors occur.
-
Efficient Cache and Buffer Management: Managing blocks in fixed sizes allows optimization of the system's cache and buffer management, improving the performance of data read and write operations.
-
Dynamic File Size Expansion: Block-based file systems can dynamically expand or shrink file sizes by allocating or releasing additional blocks as needed.
-
Minimized Data Fragmentation: Dividing files into uniformly sized blocks reduces file fragmentation on disk. This allows data to be stored and read from contiguous disk areas, improving performance.
HDFS Block Size: 128MB
HDFS (Hadoop File System) has a much larger default block size of 128MB. This is because Hadoop was inherently designed to process large-scale data, making it optimized for streaming rather than random processing. Additionally, a larger block size means smaller metadata, which reduces NameNode overhead and is advantageous from a management perspective.
For a Hadoop NameNode, it is generally said that 1GB of heap memory is used to store 1 million blocks.
Quiz
Q1: What is the main topic covered in "What is a Block-Based File System? HDFS Block File
System."?
Learn about block-based file systems and compare them with HDFS.
Q2: What is Advantages of Block File Systems?
Concise Metadata: Since each block has a fixed size, there is no need to explicitly store the
location and size of each block in the file metadata. This reduces the complexity of the metadata.