- Authors

- Name
- Youngju Kim
- @fjvbn20031
HDFS Architecture
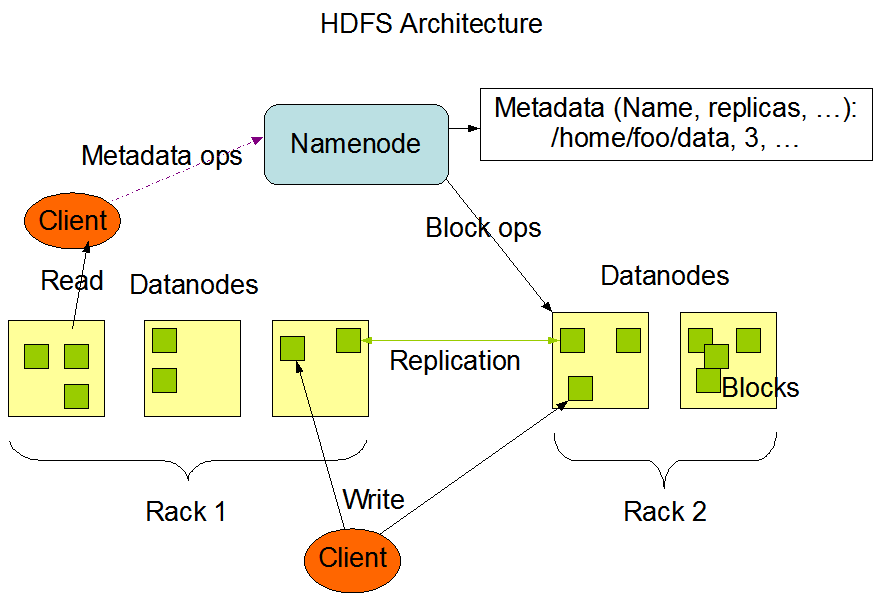
The HDFS architecture can be broadly divided into two components as shown in the diagram above: the NameNode, which stores metadata about the file system, and the DataNode, which stores the actual data. Data split into blocks is managed by processes called DataNodes that reside on worker nodes, and the NameNode stores information about where these data blocks are located and how they are replicated. To retrieve data, a client must first access the NameNode to obtain block location information before accessing the DataNode.
NameNode
- fsimage: Block metadata is stored in the NameNode's memory to ensure real-time performance. For persistence, this metadata is periodically saved as a snapshot file, known as the fsimage.
- edit log: Maintains a record of all changes made since the most recent fsimage.
- DataNode Monitoring: DataNodes send heartbeat signals to the NameNode to indicate their status. If no heartbeat is received within a specified time period, the NameNode considers that DataNode a dead node.
- Replica Management: Since DataNodes can go down at any time, blocks are configured to be replicated across multiple DataNodes arranged in a pipeline. The default replication factor is 3, and to prevent data loss even when an entire rack goes down, rack awareness is applied to avoid storing all copies of a block on a single rack.
- Access Control: Manages access to files and directories based on the user or group information of those accessing the NameNode.
DataNode
Data Storage: The DataNode stores actual data blocks in HDFS. It receives data from clients or other DataNodes, stores it on the local file system, and reads and transmits the data when needed.
Data Replication: To ensure fault tolerance, HDFS replicates each data block across multiple DataNodes. Following instructions from the NameNode, a DataNode replicates data blocks to other DataNodes or receives and stores data blocks from other DataNodes.
Heartbeat and Block Report: DataNodes periodically send "heartbeat" messages to the NameNode to report their status and capacity. They also send a "block report" at regular intervals, which is a list of all data blocks they hold.
Data Verification: DataNodes periodically inspect stored data blocks to verify data integrity. Through these inspections, data errors or corruption can be detected and addressed.
Client Request Handling: When a client requests to read or write data, the DataNode processes the request by transmitting or receiving the data.
Deletion and Relocation: Following instructions from the NameNode, a DataNode can delete data blocks or move them to other DataNodes. This is done to efficiently utilize storage space and meet replication factor requirements.
Block Recovery: If a block is corrupted or inaccessible, a DataNode can recover it from replicas stored on other DataNodes.