- Authors

- Name
- Youngju Kim
- @fjvbn20031
Files and Blocks
On a typical computer, a single file is stored across multiple blocks, and the block size is usually 512 bytes (though it may vary depending on the operating system or configuration). For example, when storing a 1MB file, it would be divided and stored across approximately 20 blocks of 512 bytes each.
If the block size is too small, the number of blocks increases, leading to greater metadata overhead. On the other hand, if the block size is too large, there is an increased risk of wasted space. For instance, if the block size is 128MB, then regardless of whether you are storing a 1MB file or a 5MB file, a 128MB block must be allocated, and the remaining space in that block cannot be used for other data.
Advantages of Block File Systems
Concise Metadata: Since each block has a fixed size, there is no need to explicitly store the location and size of each block in the file metadata. This reduces the complexity of the metadata.
Efficient Disk Usage: Dividing data into fixed-size blocks optimizes disk space allocation and minimizes free space on the disk, improving overall disk utilization.
Fast Random Access: Block-based access makes it easier to access data at arbitrary locations. Since the calculation needed to locate a specific block is straightforward, random access performance is improved.
Strong Fault Tolerance: Some block file systems provide additional error detection and recovery mechanisms at the block level. These mechanisms help ensure the integrity of each block and allow recovery of only the affected block when errors occur.
Efficient Cache and Buffer Management: Managing blocks in fixed sizes allows optimization of the system's cache and buffer management, improving the performance of data read and write operations.
Dynamic File Size Expansion: Block-based file systems can dynamically expand or shrink file sizes by allocating or releasing additional blocks as needed.
Minimized Data Fragmentation: Dividing files into uniformly sized blocks reduces file fragmentation on disk. This allows data to be stored and read from contiguous disk areas, improving performance.
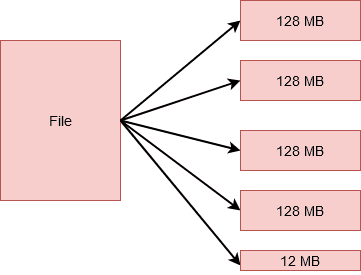
HDFS Block Size: 128MB
HDFS (Hadoop File System) has a much larger default block size of 128MB. This is because Hadoop was inherently designed to process large-scale data, making it optimized for streaming rather than random processing. Additionally, a larger block size means smaller metadata, which reduces NameNode overhead and is advantageous from a management perspective.
For a Hadoop NameNode, it is generally said that 1GB of heap memory is used to store 1 million blocks.